Каталог
Графическая частьК сожалению, архитектура VLIW4 (родом из семейства видеочипов AMD Cayman) в качестве основы встроенной графики в процессорах Trinity/Richland появилась сразу после завершения перехода десктопной части уравнения в направлении VLIW5/VLIW4 => GCN, а ведь наличие линейки продуктов с сильно разнесёнными графическими архитектурами никому особо не нужно, тем более разработчикам. Заглядывая вперёд, отметим, что решение следовать путём GCN было правильным, ведь сейчас GPU в Kaveri использует архитектуру GCN, которая находит применение и в десктопном high-end чипе R9-290X на ядре Hawaii.  Данный шаг позволил AMD с минимальными либо даже с нулевыми усилиями представить весь функционал, предлагаемый сегодня GPU Hawaii – например, технологию TrueAudio, а также улучшенные блоки Video Coding Engine и Unified Video Decoder. Другое дело, решит ли AMD создать APU с более чем 8-ю вычислительными блоками GCN, и в этом случае возникает вопрос о заинтересованности потребителя в APU AMD ещё более высокого класса с гораздо более мощной графикой. Хотя здесь возникают проблемы с пропускной способностью памяти, действительно важным является ответ на вопрос о потребности сообщества в таких APU – подобных тем, что используются в игровых консолях Xbox One и PS4. Llano, Trinity и Kaveri: сравнительный анализ железаСравнение предоставленного AMD чёткого снимка кристалла Kaveri с аналогичными фотографиями кристаллов APU двух предыдущих поколений даёт достаточно полное представление об эволюции APU AMD.
Переход с Llano на Trinity характеризуется «съёживанием» полноценной 4-ядерной системы до 2-модульной компоновки – актуального на сегодняшний день тренда в области APU AMD. Переход с Richland на Kaveri – более серьёзный шаг вперёд, чем можно себе представить. AMD APU: характеристики
Рассматривая ситуацию с APU Llano, Trinity и Richland в ретроспективном аспекте, чётко осознаёшь сложность проблемы, связанной с повышением плотности размещения транзисторов при переходе к техпроцессу GF 32 нм SOI, что хорошо демонстрирует представленная ниже таблица. Следует, однако, иметь в виду, что, кроме Intel, никто нормально не документирует процедуру подсчёта/оценки количества транзисторов, и в этой связи остаётся только надеяться на последовательность AMD в реализации метода подсчёта транзисторов для CPU и GPU (хотя здесь мы, возможно, выдаём желаемое за действительное). Плотность размещения транзисторов
Если AMD и в самом деле одинаково считает транзисторы во всех APU/GPU, тогда переход к Kaveri не выглядит таким уж экстремальным – скорее речь идёт о хорошем прогрессе с точки зрения промежуточного положения между APU предыдущих поколений и других графических решений AMD на базе GCN. При сравнении с чисто процессорными (не графическими) архитектурами AMD становится очевидна гораздо большая степень «утрамбовки» APU вследствие того, что значительная площадь кристалла APU приходится на встроенное видео. Технология TrueAudioВ рамках технологической составляющей APU Kaveri производитель фокусирует внимание на добавлении и обновлении специализированных функциональных блоков и модулей, призванных ускорить выполнение тех или иных задач. Переход к графической архитектуре GCN позволил разработчикам использовать преимущества технологии TrueAudio, реализованной в виде цифрового сигнального процессора (сопроцессора), для улучшения звуковой атмосферы в играх. Также обновлению подверглись блоки Video Codec Engine (VCE) и Unified Video Decoder (UVD). Все крупнейшие производителя графических решений для настольных компьютеров – AMD, NVIDIA, Intel – продвигают новые технологии, способствующие созданию более благоприятных условий пользования своими продуктами, что, очевидно, предполагает многообразие подходов с учётом различных аспектов: игры, вычисления, потребление контента, повышение энергоэффективности, увеличение производительности и т.д. Всё это объясняет распространение таких функций/технологий, как FreeSync, G-Sync, QuickSync, OpenCL и тому подобных. Новой функцией AMD является TrueAudio – полностью программируемый специализированный аппаратный блок с функцией разгрузки процессора в задачах обработки аудио.  Основная проблема, связанная с разработкой новых инструментов, сводится к ответу на вопрос о том, предполагает ли их реализация следование общим принципам или ставка делается на специализированное железо. Это, в свою очередь, сводится к разграничению между встроенными в CPU ресурсами и специализированным железом в виде чипа ASIC (application-specific integrated circuit – интегральная схема специального назначения) в качестве исполнительного элемента для той или иной задачи. Если задача специфична и статична (не подвержена изменению во времени), целесообразно использовать ASIC благодаря малым размерам, связанным с энергопотреблением низким накладным расходам и высокой пропускной способностью. Выбор в пользу CPU предпочтителен для изменяемой во времени задачи, лишённой чётких очертаний, и здесь открываются новые горизонты в плане гибких возможностей в обмен на компромисс с производительностью на Ватт. Мощность современных процессоров обуславливает доступность целого ряда технологий в области аудио с оптимизацией алгоритмов обработки. Единственным ограничением в этом плане является воображение разработчика и широта художественного замысла дизайнера. Реализация фильтра аудиоэффектов в игре на лету посредством CPU может вызвать весьма серьёзную нагрузку, особенно при сохранении эффекта в течение длительного времени. На слайде AMD показан пример добавления одного эффекта реверберации (convolution reverb) к аудиосэмплу, демонстрирующий возрастание нагрузки на CPU с увеличением длительности эффекта.  Данный пример характеризует применение одного фильтра к одному аудиосэмплу. А теперь представьте игровую сцену: пожар, со всех сторон звучат выстрелы, шум воды из пожарных гидрантов, гремят взрывы… Применение эффектов ко всем этим действиям с последующим перемещением источника звука с учётом его фактического местонахождения в игровой сцене влетит в копеечку с точки зрения вычислительных ресурсов – всё ради реализма. Вот здесь на сцену выходит технология TrueAudio, призванная переложить всё на плечи специализированного железа, заточенного под быстрое решение подобного рода задач.  TrueAudio также реализована в видеокартах новейшего поколения R9 260 и R9 290 – по существу, везде, где графическая архитектура представлена как минимум платформой GCN в версии 1.1 и выше. Между тем, известно, что блок обработки аудио в PlayStation 4 также базируется на технологии TrueAudio. Впрочем, изолированный характер эволюции игровых консолей не позволяет сделать однозначный вывод касательно использования одних и тех же API в этих разных платформах. AMD, со своей стороны, сотрудничает с разработчиками звуковых плагинов уровня связующего программного обеспечения (wwise, Bink) с целью содействия развитию экосистемы TrueAudio, так что даже в случае различающихся API разработчики связующего ПО могут абстрагироваться от этих различий, сфокусировав внимание на общих моментах в основе аппаратной платформы. Как это обычно бывает с дополнительным аппаратным функционалом подобного рода, использование TrueAudio в играх потребует написания особого кода, и как таковая реализация преимуществ TrueAudio будет определяться конкретной игрой. В то же время сегодня на рынке не представлены игры, способные использовать преимущества новейшей технологии AMD в области звука, и в этом случае аппаратная часть опередила программную. Вот три первых игровых проекта с поддержкой TrueAudio в списке AMD: Murdered: Soul Suspect, Thief, Lichdom. Во многом аналогично технологии FreeSync, здесь, вероятно, действует правило «лучше 1 раз увидеть, чем 100 раз услышать». UVD и VCE в новой редакцииОтдельного упоминания заслуживают обновлённые функциональные блоки UVD (Unified Video Decoder) и VCE (Video Codec Engine) в чипах Kaveri. Перед нами UVD 4, обновлённый с учётом способности быстро справляться со сбоями в обработке видео формата Н.264, и VCE в версии 2. Из этих решений наибольший интерес представляет улучшенный VCE. Способность ссылаться на два соседних кадра в потоке как результат добавления поддержки B-кадров при кодировании видеопотока в формат H.264 должна помочь повысить качество изображения на выходе VCE-блока и/или снизить нужный битрейт с учётом уровня качества в каждом конкретном случае. Между тем, добавление поддержки более качественного цветового пространства YUV444 в кодировщике H.264 позволит улучшить сжатие преимущественно штриховой графики или текста, что, в свою очередь, имеет немаловажное значение для чёткости картинки, передаваемой на беспроводной дисплей.   Рассматривая тематику архитектуры гетерогенных систем (HSA – Heterogeneous System Architecture), технологии общей памяти (hUMA – Heterogeneous Unified Memory Architecture) и гетерогенной очереди (hQ – Heterogeneous Queuing), штатный эксперт AnandTech Рауль Гарг (Rahul Garg) обсуждает рабочие моменты, связанные с реализацией, смысловым наполнением и применением данных концепций. Графическая архитектура заточена под решение хорошо распараллеленных задач, к числу которых относятся, например, операции с матрицами, которые обычно «дружат» с GPU. Однако не каждая задача такого рода подходит для решения средствами GPU. В современных условиях использование GPU в большинстве задач требует копирования данных между CPU и GPU. Для дискретной видеокарты типична картина, когда данные по шине PCIe копируются из системной памяти в видеопамять, там происходит обсчёт, по завершении которого готовый результат обратно пересылается по шине PCIe. Например, прибавление матрицы является хорошо распараллеливаемой операцией, выполнение которой достаточно подробно описано и задокументировано как для CPU, так и для GPU, однако в зависимости от структуры оставшейся части приложения выполнение этой задачи средствами GPU может оказаться нецелесообразным, если копирование данных по PCIe вредит быстродействию приложения в целом. В приведённом примере передача данных как таковая зачастую обходится дороже, чем выполнение операции сложения для матрицы средствами CPU. Необходимость копирования данных между CPU и GPU также усложняет процесс написания программного обеспечения.  Необходимость скоростной передачи данных в современных условиях обусловлена двумя причинами. Во-первых, обсчёт средствами GPU сегодня обычно предполагает наличие дискретной графики, подключённой к компьютеру по шине PCIe. Дискретные видеоадаптеры имеют собственную память, объём которой обычно варьируется в диапазоне 1-4 Гб, но может достигать и 12 Гб в некоторых современных графических ускорителях для серверов. Видеопамять (например, GDDR5) может обладать высокой пропускной способностью, позволяющей скрыть задержки в промежутке между переключениями контекста потока, поэтому её иногда называют чашей Грааля в вычислениях, требующих активного обращения к памяти. В такой конфигурации, даже с учётом допущения о возможности GPU осуществлять чтение/запись данных при работе с системной памятью по шине PCIe, зачастую более эффективно единоразово пробросить все необходимые данные в видеопамять GPU, где вычислительные ядра будут читать/записывать данные с обращением к родной графической памяти в противовес к обращению к системной памяти по шине PCIe в ущерб быстродействию. Во-вторых, CPU и GPU имеют дело с разными адресными пространствами, которые до появления HSA они «не разумели». Даже встроенная графика, использующая ту же физическую память, лишена механизма, необходимого для работы с общим адресным пространством. Технология HSA призвана решить эту проблему. Арсенал средств, позволяющих избежать накладных расходов при передаче данных, довольно обширен. Например, можно попытаться передать данные в параллельном режиме, попутно возложив часть вычислений на плечи CPU и обеспечив частичное совпадение во времени вычислительных процессов и процессов передачи данных. В ряде случаев можно обойтись без CPU – например, пробросив данные в виде файлов с SSD, оснащённого интерфейсом PCIe, напрямую в GPU посредством технологии GPUDirect. Однако такие методы не всегда применимы и требуют от программиста значительных усилий. В конечном счёте, наличие по-настоящему общей памяти для CPU и GPU позволит решить множество проблем, хотя дискретная графика с быстрой видеопамятью отлично подходит для множества других задач, несмотря на проблему накладных расходов при копировании данных. Общая память: как это было до HSAТермины «совместно используемая память» (shared memory), или «общая память» (unified memory), довольно свободно используются в отрасли и могут иметь разные значения в зависимости от контекста. Рассмотрим текущую ситуацию с учётом специфики поставщиков платформ. NVIDIA впервые упоминает термин «общая память» (unified memory) в связи с технологией CUDA. Однако для видеочипов NVIDIA текущего поколения реализация данной концепции, предполагающая задействование программной части в качестве основы, является скорее решением для облегчения труда программистов, скрывающимся за спиной API для простоты использования. Перенос данных всё так же идёт в ущерб производительности, и инструментарий NVIDIA просто скрывает некоторые сложности, связанные с работой ПО. Концепцию по-настоящему общей памяти NVIDIA, как ожидается, предложит в продуктах с архитектурой Maxwell, которая, вероятно, увидит свет в преемнике чипа Tegra K1 в 2015-2016 гг. AMD хвалится «нулевым копированием» в чипах Llano и Trinity в OpenCL-программах, хотя в основном это лишь обеспечивает возможность в ограниченном числе случаев быстро скопировать данные с CPU в GPU и способность вновь считать данные с GPU. На практике функция нулевого копирования имеет ограниченное применение вследствие ряда факторов, включая «дороговизну» этапа инициализации. В большинстве случаев в условиях реальной эксплуатации придётся копировать данные между CPU и GPU. Сегодня Intel предлагает некоторую поддержку разделяемой памяти в графике 7-го поколения в составе процессоров Ivy Bridge и Haswell, выраженную посредством OpenCL и DirectX. В плане перспективы совместного доступа к памяти предложенный Intel механизм интеграции CPU с GPU впечатляет больше, чем таковой в APU Llano/Trinity, но его задействование по-прежнему ограничено несколькими простыми случаями из-за невозможности совместного доступа к памяти с использованием указателей адресов, вызова страниц по запросу и обеспечения по-настоящему совместного использования памяти CPU и GPU, предлагаемых в рамках концепции HSA, что позволяет говорить о значительном превосходстве AMD в этом вопросе. Другие компании, такие как ARM, Imagination Technologies, Samsung и Qualcomm, также входят в состав консорциума HSA Foundation и, вероятно, работают над созданием аналогичных решений. Графические ядра Mali T600 и T700 демонстрируют некоторую способность совместного использования GPU- и CPU-компонентами графической буферной памяти посредством OpenCL 1.1. Однако есть мнение, что в ближайшем будущем лишь AMD сможет обеспечить полный спектр возможностей HSA. По состоянию на сегодняшний день, реализованная в чипах Kaveri модель HSA – самый прогрессивный пример тесного взаимодействия CPU и GPU, являющийся наиболее полным решением такого рода. HSA и hUMAА теперь о том, как функционал общей памяти реализован в рамках HSA. Основные преимущества от единой памяти в рамках HSA сводятся к адресуемому пространству памяти. Снижение платы за возможность доступа CPU и GPU к одним и тем же данным позволяет добиться повышения эффективности решения вычислительных задач или разгрузки вычислительных ресурсов, не беспокоясь о цене такой операции.  Отказ от копирования данных от CPU к GPU и обратно: теперь GPU может осуществлять доступ ко всему адресному пространству CPU без необходимости копирования. Примером является упомянутое выше сложение матриц. Система с поддержкой HSA позволяет избежать копирования входных данных в GPU и копирование результата назад в CPU. Доступ к адресному пространству в полном объёме: помимо выигрыша в производительности в результате отказа от копирования данных, GPU также лишается ограничений по объёму встроенной видеопамяти, что обычно имеет место в случае с дискретными видеокартами. Даже топовые ускорители графики сегодня имеют максимум 12 Гб видеопамяти, в то время как CPU выгодно отличается способностью осуществлять доступ к потенциально гораздо большему пространству памяти. Во многих случаях, таких как научное моделирование, это означает способность GPU оперировать намного большими наборами данных без особых усилий со стороны программиста, который в противном случае должен ухитриться втиснуть данные в ограниченное адресное пространство GPU. APU Kaveri позволяют задействовать до 32 Гб памяти DDR3, и в этом случае ограничивающим фактором становится уже потребность рынка в нерегистровых модулях памяти объёмом 16 Гб без ECC. Наличие задержек при работе APU с памятью DRAM означает возможность улучшения ситуации в будущем за счёт использования объёмного кэша L3 либо памяти eDRAM, особенно в сценариях, когда даёт о себе знать не бесконечная пропускная способность памяти либо при загрузке данных с необходимостью предварительного освобождения памяти. Адресация общей памяти на аппаратном уровне – значимое нововведение для Kaveri и HSA, которое на данный момент не предлагает ни одна другая система. Приложения выделяют под свои нужды часть памяти в пространстве виртуальной памяти CPU, при этом операционная система ведёт таблицу трансляции (пересчёта) виртуальных адресов в физические. При получении команды на загрузку CPU преобразует виртуальный адрес в физический, и здесь ему на помощь может прийти операционная система. GPU также имеет собственное виртуальное адресное пространство, и раньше GPU ничего не смыслил в адресном пространстве CPU. В системах с общей памятью предыдущего поколения, таких как Ivy Bridge, приложению приходилось просить видеодрайвер составить таблицу соответствия страницам памяти GPU по конкретному диапазону виртуальных адресов CPU. Это работало в случае с простыми структурами, такими как массивы, но не работало для более сложных структур. Инициализация таблицы соответствия страницам GPU сопровождалась дополнительными непроизводственными затратами в ущерб производительности.  HSA позволяет GPU напрямую осуществлять загрузку/сохранение при работе с виртуальным адресным пространством CPU. Таким образом, приложение может напрямую передать центральному процессору указатели, способствуя использованию преимуществ GPU значительно более обширным классом приложений. Например, совместный доступ к связному списку и другим структурам данным, использующим указатели, теперь возможен без ухищрений со стороны приложения. Отсутствие накладных расходов в работе драйвера при совместном доступе к указателям способствует повышению эффективности.  Такое решение позволяет CPU и GPU осуществлять одновременный доступ к одному и тому же набору данных и его совместную обработку, способствуя реализации программистами рабочих сценариев с высокой загрузкой мощностей и достижению уровня, близкого к рассчитанным AMD 800 GFLOPS и выше для одного Kaveri. При наличии до 12 вычислительных ядер, несмотря на различия в способе использования вычислительных ядер в CPU и GPU и на различия в исполняемых программных ядрах (kernel), все они, по крайней мере, могут осуществлять доступ к одним и тем же данным с нулевыми накладными расходами. Обеспечение совместного использования данных путём устранения барьеров и преодоления препятствий при работе с потоками всё же остаётся в ведении программиста. Вызов страниц по запросу. В приведённом выше описании за кадром осталась одна деталь. Пересчёт виртуальных адресов в физические - задача не простая, и страница, содержащая требуемые данные с учётом необходимости их нахождения в физической, т.е. оперативной, памяти, может фактически отсутствовать в оперативной памяти, предполагая, таким образом, необходимость загрузки этой страницы, скажем, с диска, что требует вмешательства операционной системы. Это называется вызов страниц по запросу (demand-driven paging). До выхода Kaveri графическое ядро было лишено возможности подкачки страниц из виртуальной памяти по запросу. Напротив, приложению приходилось заранее знать диапазон адресов, к которым осуществляется доступ, и привязывать его к объекту данных, находящемуся в видеопамяти; затем видеодрайвер блокировал соответствующие страницы в оперативной памяти. Однако зачастую бывает так, что программист, пишущий приложение, не знает заранее схему доступа к данным. Использующие указатели структуры данных, такие как связанные списки, где узловые структуры могут содержать указание на любое место в памяти, представляли сложность для программиста. Вызов страниц по запросу вместе с общей адресацией позволяет осуществлять совместный доступ CPU и GPU к произвольным структурам данным, значительно расширяя список приложений, получающих возможность ускоренного выполнения средствами GPU. Тесное взаимодействие CPU и GPU. Ранее обсуждалась возможность выполнения GPU-частью операций чтения/записи с обращением к адресному пространству CPU без необходимости копировать данные. Однако это ещё не вся история, т.к. порой CPU и GPU хотят объединить усилия для выполнения той или иной задачи. В ряде случаев решающее значение имеет взаимная способность CPU и GPU видеть записываемые результаты вычислений – непростая задача в силу ряда проблем, включая работу кэш-памяти. Модель памяти HSA обеспечивает дополнительную связность в работе CPU и GPU посредством инструкций, использующих временное блокирование доступа к определённой части памяти со стороны других исполнительных устройств. Однако, поскольку такая связность не проходит даром для производительности, HSA предоставляет в распоряжение программиста механизмы, позволяющие чётко обозначить отсутствие необходимости совместной работы CPU и GPU. Помимо инструкций, предполагающих обращение к связной памяти, HSA допускает возможность использования атомарных инструкций, позволяющих CPU и GPU осуществлять атомарные запись/чтение по конкретному месту в памяти. Эти атомарные действия в рамках данной платформы рассчитаны на функционирование как обычные атомарные действия, что предполагает выполнение операции по схеме «чтение-изменение-запись» в рамках одной инструкции без создания специфичных препятствий/блокирований в отношении элемента данных или набора данных. HSAILСтремление HSA Foundation обеспечить работу одних и тех же приложений на базе гетерогенных вычислений в среде всех систем с поддержкой HSA вызвало необходимость стандартизации программного интерфейса, поддерживаемого любой HSA-системой. HSA Foundation хотела создать низкоуровневый API для железа, которое может служить целевой платформой для компиляторов в разных языках программирования. Обычно компиляторы ориентируются на поддерживаемый тем или иным процессором набор команд, однако в условиях нацеленности концепции HSA на разнофункциональное аппаратное обеспечение (центральный процессор, графический процессор, специализированный сопроцессор) истинная стандартизация наборов команд не представляется возможной. В противоположность этому HSA Foundation подвергла стандартизации псевдонабор команд, получивший название HSAIL (HSA Intermediate Language). Идея такова: компилятор языков высокого уровня, таких как OpenCL, C++ AMP или Java, генерирует HSAIL-код, после чего HSA-драйвер посредством компиляции «на лету» генерирует собственно машинный код. Идея псевдонабора команд не нова: ранее она уже использовалась в рамках портируемых решений, таких как байт-код Java и байт-код Direct3D. HSAIL является достаточно низкоуровневым решением, чтобы «обнажить» возможности железа с учётом множества детальных аспектов; данная платформа тщательно продумана с прицелом на очень быстрое преобразование HSAIL в машинный код.  Конкурентом HSAIL является PTX от Nvidia, преследующий схожие с HSAIL цели. Хотя PTX предназначен только для системных решений Nvidia, ряд научно-исследовательских проектов использует PTX для специфических расчётов, например, тех, что ориентированы на х86 процессоры. HSAIL можно будет портировать на любые GPU, CPU и DSP (сопроцессор) с поддержкой HSA API. Гетерогенная очередь (hQ)Для неспециалиста термин «гетерогенная очередь» звучит весьма туманно. В действительности речь идёт о части кода, использующей в процессе исполнения вызов другой функции, требующей обращения к другому устройству. Рассмотрим пример с программой, предполагающей выполнение математических расчётов, когда части исполняемого средствами GPU кода требуется помощь CPU. То, как в этом случае система оперирует вычислительными потоками, называется «гетерогенная очередь», и в контексте данной концепции HSA предлагает 3 новые функции в APU Kaveri и других HSA-системах в сравнении с APU предыдущих поколений. Очерёдность исполнения в пользовательском режиме. В большинстве API с поддержкой GPGPU за формирование очереди задач/программных ядер на исполнение средствами GPU отвечает центральный процессор, при этом построение очередности осуществляется средствами видеодрайвера и требует системных вызовов. Однако HSA позволяет формировать очередь в пользовательском режиме с возможностью сокращения накладных расходов, связанных с отправкой задач. Меньшие задержки с отправкой способствуют эффективному управлению очередности выполнения средствами GPU даже сравнительно небольших задач. Динамический параллелизм. Стандартно формирование очерёдности задач для GPU ложится на плечи CPU, при этом GPU не может формировать очередь сам для себя. С выходом видеопроцессора GK110 в основе графической карты GeForce Titan компания Nvidia реализовала возможность вызова одними программными ядрами GPU других программных ядер GPU, использовав определение «динамический параллелизм». Это же явление наблюдается в случае HSA-систем.  Функции обратного вызова CPU. С выходом APU Kaveri в очередь могут добавляться функции обратного вызова, рассчитанные на выполнение средствами как CPU, так и GPU, причем GPU теперь сможет не только сам формировать очередь задач, но и обращаться к ресурсам CPU для выполнения части задания. Таких возможностей у конкурирующих решений нет. Обратные вызовы с обращением к CPU во многих случаях могут оказаться весьма полезны, например, при необходимости вызова системных API, не способных выполняться средствами GPU, при использовании обычного CPU-кода, ещё не портированного для выполнения на GPU, или в случае с кодом, выполнение которого посредством GPU представляется нецелесообразным в силу повышенной сложности. Инструменты программированияМногообразие языков программирования определило универсальный подход AMD к созданию инструментов программирования.  Рассмотрим дорожную карту AMD в области программного обеспечения в части разработки инструментов программирования для HSA: Основной стек HSA. Доступность основного стека исполнения HSA с поддержкой HSAIL и среды выполнения HSA для Kaveri ожидается начиная со 2-го квартала 2014 года.  LLVM. HSAIL - всего лишь часть мозаики. Тогда как многих программистов, пишущих компиляторы, вполне устраивает возможность генерации HSAIL-кода непосредственно компилятором, сегодня многие компиляторы создаются на базе таких инструментов, как LLVM (Low Level Virtual Machine). AMD также предоставит в рамках open-source концепции (продукт с открытым исходным кодом) генератор HSAIL-кода для LLVM, позволяющий разработчикам компиляторов использовать LLVM для генерации HSAIL с минимальными трудозатратами. Таким образом, однажды в будущем мы, в конечном счёте, сможем увидеть компиляторы для таких языков программирования, как C++, Python и Julia, ориентированные на HSA-системы. Работа в Clang с поддержкой OpenCL и с генератором HSAIL на базе LLVM упростит работу по встраиванию OpenCL-драйверов для систем на базе HSA. Говоря о конкурентах, отметим, что NVIDIA в PTX уже предлагает решения уровня «вычислительный узел» (backend) для LLVM. OpenCL. На момент релиза APU Kaveri поддерживают OpenCL в версии 1.2. По мнению эксперта с AnandTech, драйвера, доступные на момент выпуска, не обеспечивают функционал стека исполнения HSA, а функционал OpenCL строится на базе обычного графического стека на основе AMDIL. Во 2-м квартале 2014 года должен выйти драйвер в версии preview с поддержкой OpenCL 1.2, реализующий некоторые расширения единой памяти на основе OpenCL 2.0 на базе инфраструктуры HSA. Выпуск драйвера с поддержкой OpenCL 2.0, созданного на базе инфраструктуры HSA, ожидается в 1-м квартале 2015 года.  C++ AMP. Инициатором проекта C++ AMP является корпорация Microsoft, и стек Microsoft строится на базе DirectCompute, который, строго говоря, не позволяет раскрыться потенциалу объединённой памяти, и даже Direct3D 11.2 делает лишь первые шаги в этом направлении. Реализация созданной Microsoft библиотеки C++ AMP нацелена на DirectCompute, что означает отсутствие возможности в полном объёме использовать преимущества функционала систем с поддержкой HSA. Между тем, C++ AMP является открытой спецификацией, допускающей возможность использования программистами других IT-компаний, пишущими компиляторы на базе C++ AMP. Multicoreware, член ассоциации HSA Foundation, совместно с AMD работает над созданием использующего C++ AMP компилятора, способного генерировать HSAIL-код для платформ с поддержкой HSA, а также над созданием промежуточного представления SPIR (Standard Portable Intermediate Representation) на базе OpenCL для других платформ, таких как платформы Intel.  Проект "Sumatra" и API Aparapi. В арсенале AMD уже имеется API, под названием Aparapi, компилирующий аннотированный Java-код для OpenCL. AMD обновит API Aparapi в этом году на предмет использования преимуществ HSA в Java 8. Кроме того, корпорация Oracle, владелец Java, также объявила о планах следования в направлении HSA посредством генерации HSAIL из байт-кода Java в своей виртуальной машине HotSpot VM (данная возможность, как ожидается, появится в Java 9 в 2015 году). Интересно будет узнать, сможет ли IBM, объявившая о партнёрстве с NVIDIA, также обеспечить поддержку HSA на уровне вычислительного узла в своей виртуальной машине Java. HSA: ЗаключениеВ целом на данный момент архитектура гетерогенных систем (HSA) значительно расширяет возможности в сравнении с базовым функционалом вычислений общего назначения (GPGPU) в платформах AMD. Концепция общей памяти в рамках HSA – сулящий великолепные перспективы шаг вперёд, предлагающий чёткий отказ от практики копирования данных, позволяющий GPU использовать адресацию обширных пространств памяти и реализующий совместный доступ CPU и GPU к сложным структурам данных. Способность GPU самостоятельно формировать очередь программных ядер (kernel) для выполнения своими силами и даже оперировать очередью обратных вызовов CPU тоже заслуживает всяческих похвал. Схема тесного взаимодействия CPU и GPU в рамках HSA определённо ставит AMD на голову выше конкурентов, потенциально позволяя в будущем ещё больше уровнять в правах CPU и GPU. Как программист, вплотную работающий с компиляторами, эксперт с AnandTech считает, что в плане программирования HSA-системы облегчат жизнь тем, кто занят написанием и компиляторов, и приложений, а в долгосрочной перспективе HSA-системы потенциально могут способствовать усилению акцента гетерогенных вычислений на массовость.  Однако лицезреть HSA вживую можно будет только тогда, когда экосистема программного обеспечения позволит использовать преимущества функционала HSA, а случится это не завтра. Хотя HSA впечатляет своими возможностями на архитектурном уровне, AMD также необходимо вплотную заняться программной частью, причём в ближайшее время. Речь идёт не только о драйверах с поддержкой HSA, но и о таких моментах, как профилирование и отладка, качественное документальное сопровождение и другие фрагменты мозаики, включая решения уровня вычислительного узла для LLVM. Также хотелось бы видеть больше проектов, предполагающих компиляцию языков программирования с ориентацией на поддержку HSA, особенно open source библиотек, над созданием которых в рамках проекта HSA трудится AMD. Наконец, успех либо провал HSA также будет зависеть от выбранного направления движения участников HSA Foundation, таких как Qualcomm, ARM, TI, Imagination tech и Samsung. На сегодняшний день лишь AMD анонсировала аппаратные продукты с поддержкой HSA. Инициатива AMD может встретить холодный приём в среде программистов, если влияние HSA ограничится платформами AMD, и идея о том, чтобы сделать программирование для гетерогенных систем частью фундаментальных принципов работы программистов новой волны, будет укореняться медленно. Не исключено, что свет увидят и другие продукты с поддержкой HSA от других игроков рынка, но тут важную роль играет фактор времени. Конкуренты, такие как NVIDIA и Intel, тоже не сидят сложа руки и в скором времени мы увидим более качественные встроенные решения для гетерогенных вычислений также и от этих компаний. Говоря о дне сегодняшнем, следует отдать должное AMD за вклад в развитие отрасли и за способность предложить решение в сфере гетерогенных вычислений, обладающее самой высокой на сегодня степенью интеграции. [N5-В фокусе – GPU] Переход с VLIW4 на GCN очень логичен. Вместо постоянной рассинхронизации APU Kaveri теперь получат ту же архитектуру, что и дискретные видеокарты с ядром Hawaii, а именно GCN 1.1, как в дискретных моделях – от Radeon R9 290X до Radeon 260X. Архитектурная синхронизация линеек встроенного и дискретного видео означает следующее: как только AMD что-то улучшает/оптимизирует в дискретном GPU, это скажется и на встроенной в APU графике, т.е. Kaveri тоже получат свою порцию «сладостей». Ранее обсуждались улучшения для TrueAudio, UVD и VCE, и вот на очереди другая значимая разработка – API Mantle. Различие в реализации архитектуры GCN в APU Kaveri (встроенное видео) и в ядре Hawaii (дискретная графика), не считая физической близости к CPU, состоит в использовании общей памяти, как об этом выше рассказал Рауль.  AMD приводит интересную статистику производительности игрового видео: судя по слайду, «в арсенале примерно трети всех пользователей Steam более слабая чем в APU A10-7850K графика». Учитывая, что встроенное в A10-7850K видео содержит 512 универсальных процессоров, хочется спросить: сколько же людей пользуются графикой в ноутбуки и нетбуках? Краткий обзор результатов исследования компании Steam позволяет сделать вывод: на первом месте интегрированные решения от Intel, на втором – дискретные карты NVIDIA среднего уровня. Велико число и тех, кто сделал выбор в пользу GPU, встроенного в другие процессоры, а также в пользу дискретных видеокарт мобильного класса, таких как Mobility Radeon HD4200. С выпуском APU Kaveri AMD, очевидно, хочет переплюнуть сразу всех, а унификация архитектур создаёт ситуацию, когда начиная с этого момента пользу от улучшений ощутят и дискретная, и интегрированная графика.  Поскольку детальный анализ ядра Hawaii на базе GCN (включая поддержку стандарта IEEE 2008, а также улучшения в таких аспектах, как блоки выборки текстур, регистры и точность вычислений) уже приводится в одном из опубликованных ранее обзоров, этот момент остался за рамками настоящего обзора. Варианты реализации архитектуры GCN 1.1 в составе дискретных видеокарт всё так же будут «рулить» в плане абсолютной вычислительной мощи, ведь с точки зрения масштабируемости потребляемой мощности (TDP) APU никогда не достигнут заоблачных высот своих «полновесных» собратьев дискретного класса, если разработка этих APU не претерпит серьёзных изменений; это, в свою очередь, означает, что таким технологиям, как HSA, hUMA и hQ, предстоит ещё долгий путь, прежде чем стать доминирующей силой. Положительный эффект от низких накладных расходов при копировании данных, достигнутый на примере APU, должен стать серьёзным прорывом в области вычислительной графики, особенно в аспектах, связанных с играми и обработкой текстур, где требуются обратные вызовы CPU.  Также дополнительным преимуществом для геймеров является тот факт, что в архитектуре GCN 1.1 все вычислительные блоки работают асинхронно и позволяют осуществлять независимое планирование для разных заданий. По сути, это означает, что при выполнении задания 8 вычислительных блоков в APU A10-7850K high-end класса работают как 8 мини-GPU.  Серьёзным препятствием на пути раскрытия всего потенциала улучшений AMD в плане фронтенда графических вычислений является ограниченная пропускная способность 2-канальной памяти DDR3. Следовательно, имеются возможности для повышения производительности путем увеличения канала пропускания памяти. Не удивительно, если для решения этого вопроса AMD прибегнет к некоторому подобию промежуточного кэша L3 или памяти eDRAM. API MantleКрупным нововведением для GCN должен стать Mantle – низкоуровневый интерфейс прикладного программирования для разработчиков игровых движков, ориентированный на повышение производительности GPU и снижение накладных расходов CPU, связанных с отправкой запросов на отрисовку. Здесь речь фактически идёт о сценариях, ограниченных производительностью в однопоточном режиме, и это тот случай, когда AMD определённо может потребоваться помощь. Хотя AMD, надо полагать, в конце концов, займётся решением вопроса с традиционно менее выигрышным положением в сравнении с Intel по однопоточной производительности, принятие на вооружение концепции Mantle может оказать APU Kaveri неоценимую помощь. Очевидным минусом является то, что темпы распространения Mantle на данный момент в лучшем случае можно назвать ограниченными.    Хотя реальный выход Mantle задержался из-за проблем с Mantle-патчем для Battlefield 4 на движке Frostbite 3, AMD с радостью заявляет о двукратном улучшении результатов в тестовом сценарии, учитывающем только вызовы API, и об улучшении плавности видеоряда до 45% в предрелизных версиях Battlefield 4. Dual GraphicsAMD кокетливо умалчивает о технологии Dual Graphics, особенно в контексте технологии сглаживания кадров frame pacing. По неволе начинаешь задаваться вопросом: а была ли вообще тема Dual Graphics – технологии повышения производительности подсистемы графики путём объединения встроенного в APU видео с дискретной картой AMD – когда-либо раскрыта в ходе официальных презентаций AMD? На проводимых в Великобритании презентациях автор обзора неоднократно обращался к представителям AMD за разъяснениями и в лучшем случае получал комментарии в духе «мы работаем над такими решениями». Сборщики компьютеров были бы очень благодарны AMD за публикацию полного списка с указанием комбинаций «встроенная графика + дискретное видео». И всё же в арсенале AMD есть интересные слайды, посвящённых Dual Graphics. В ходе внутрикорпоративного тестирования AMD объединила встроенное в APU A10-7850K видео серии R7 с дискретной картой R7 240 2GB GDDR3, что фактически наводит на мысль о возможности совместного использования любого APU с графикой R7 и любой дискретной карты серии R7 с памятью GDDR3. Стоит учесть, что AMD рекомендует проводить тестирование конфигураций с использованием Dual Graphics после выхода новой версии драйвера 13.350. Для целей тестирования в рамках настоящего обзора использовались драйвера 13.300 beta 14 и RC2, доступные на момент написания обзора. Далее приводятся результаты в том виде, как они представлены AMD, без проверки тестировщиками с AnandTech.  Следует отметить: хотя эффективность Dual Graphics до последнего времени не отличалась системным характером, с приходом Kaveri можно ожидать улучшений, если, конечно, AMD намерена развивать это направление. Во времена APU Trinity и Richland сложилась интересная ситуация, обусловленная различием архитектур интегрированной (VLIW4) и дискретной (VLIW5) графики. При этом пока абстрагируемся от того факта, что обе архитектуры отставали от новой GCN, к которой было приковано основное внимание AMD. Однако в условиях, когда встроенное и дискретное видео AMD последнего поколения использует ту же архитектуру, а также благодаря улучшениям касательно frame pacing, предпринятым за последний год, Dual Graphics оказалась в более выгодном положении как решение начального уровня для повышения игровой производительности. Впрочем, аналогично более продвинутому решению в лице Crossfire эффективность Dual Graphics как multi-GPU конфигурации всегда будет ниже в сравнении с одной, но более производительной видеокартой. AMD Fluid Motion VideoЕще одна технология AMD, используемая в APU A10-7850K и удостоенная лишь мимолётного внимания, называется Fluid Motion Video. По сути, речь идёт о повышении частоты кадров методом интерполяции с 24 Гц до 50/60 Гц для более плавного просмотра видео. Уместившееся в 1 слайд описание AMD, особенно с учётом базовых знаний в этой области у большинства пользователей, в лучшем случае можно охарактеризовать как выполненное в духе минимализма.  Тестовая конфигурацияРоль главных героев выполняют 2 представителя линейки Kaveri: топовый A10-7850K с TDP 95 Вт и A8-7600 с изменяемым в BIOS TDP, равным 65 Вт либо 45 Вт. Тесты для младшей модели проводились в обоих режимах энергопотребления, и здесь разница не превысила нескольких сотен мегагерц. В 65-ваттном режиме A8-7600 уступает A10-7700K всего 200 МГц в номинальном режиме, а в режиме Turbo частота, так совпало, оказалось равной 3,8 ГГц для обеих моделей. APU Keveri стали первыми испытуемыми, подвергшимися тестированию в условиях тестового пакета, обновлённого тестировщиками с AnandTech с учётом большей ориентации на вычислительные задачи, задачи конвертации видео с использованием различного программного обеспечения и на реальные тестовые сценарии с более чётким акцентом на профессиональных пользователей. Сайт AnandTech выражает благодарность:
Тестовая конфигурация: платформа AMD
К сожалению, тестировщикам не удалось вовремя заполучить APU Richland с TDP 65 Вт, зато 65-ваттный APU Trinity оказался под рукой. Важно отметить, что для каждой TDP-категории частота работы CPU-части и поддерживаемой памяти различаются в зависимости от архитектуры и техпроцесса. Тесты в данном обзоре проводились с максимальной частотой памяти, поддерживаемой процессором, а не с той повышенной частотой, которую может обеспечить AMD Memory Profile. Данный фактор необходимо учитывать наравне с такими аспектами, как число исполняемых команд за такт (IPC – instructions per clock) и частота работы CPU. В рамках обзора использовались несколько моделей процессоров Intel с разным TDP:
К сожалению, ассортимент процессоров Core i5 и i3 был ограничен, а чипы Core i7 для обзоров Intel предпочитает высылать тогда, когда тестируются соответствующие платформы. Впрочем, автору удалось разжиться моделью Core i3-3225, позаимствованной у своего сетевого хранилища (NAS), а также моделью Core i3 на ядре Haswell. Поскольку другой тестировщик с AnandTech в это время тестировал проектора BRIX, автор попросил коллегу запустить на базе BRIX как можно больше бенчмарков из игрового тестового пакета, чтобы оценить способность процессора Intel с интегрированной памятью eDRAM эффективно противостоять графике поколения GCN в APU Kaveri. Для полноты картины была протестирована единственная имевшаяся в наличии видеокарта среднего уровня – Radeon HD 6750, работавшая в паре с Core i7-4770K. РазгонВ завершение процедуры тестирования в рамках настоящего обзора был проведён разгон APU A10-7850K. Хотя речь идёт об инженерном образце, можно предположить, что он максимально приближен к конечному продукту, ведь именно такие обзоры служат руководством для читателя при выборе того или иного товара. Отправной точкой в процедуре разгона APU A10-7850K стало достигнутое в автоматическом (т.е. не разгонном) режиме пиковое значение напряжения питания под нагрузкой в среде OCCT, равное 1,24 В. С этой отметки тестировщики принудительно снизили напряжение питания до 1,1 В и частоту до 3,5 ГГц, оставив включёнными функцию LLC (load line calibration) и режим Turbo для поддержания частоты на близком к номиналу уровне. Процедура разгона стандартна: прогнав 5-минутный тест OCCT, PovRay и новинку 2014-го года – LuxMark, тестировщик определяет, насколько стабильно работает система. В случае проблем напряжение поднимают с шагом 0,025 В до достижения стабильной работы, после чего осуществлялся переход на новый частотный уровень посредством повышения множителя.  Переход с 3,5 ГГц к 3,6 ГГц потребовал серьезного поднятия напряжения, что, видимо, связано с исчерпанием доступных для данного техпроцесса возможностей по лёгкому достижению повышенных частот с как можно меньшим повышением напряжения, при этом система работала нестабильно, пока выставляемое в BIOS напряжение питания не достигло 1.225 В. Параллельно с разгоном процессора замерялось энергопотребление системы в простое и под нагрузкой; замеры производились на входе блока питания.  Как и следовало ожидать, повышение напряжения серьезно влияет на энергопотребление процессора. Выявлена одна особенность: даже в штатном режиме модуль материнской платы, отвечающий за питание центрального процессора (Voltage Regulator Module - VRM), очень горяч на ощупь – настолько горяч, что система без использования активного (вентиляторного) охлаждения выдавала множественные ошибки, и в процессе разгона ситуация ещё больше усугубилась. В чём дело – в платформе в целом или только в системной плате – сказать сложно. [N7-Тестирование: CPU] В центре внимания тестировщика всегда должны быть реальные бенчмарки, ведь синтетические тесты зачастую лишь частично нагружают CPU, искажая объективную картину в плане преимуществ CPU для пользователя в реальных условиях эксплуатации. Данное обстоятельство определило необходимость обновления тестового пакета 2014 года с включением большего числа задач по декодированию изображений и видео, когда 2D-картинка на входе посредством особых алгоритмов превращается в 3D-модель. Для обеспечения «обратной совместимости» результатов тесты из пакета 2013 года (как и ряд синтетических бенчмарков) перекочевали в 2014 год. Agisoft Photoscan v1.0Основным из новых бенчмарков в составе обновлённого тестового пакета AnandTech стал Agisogt Photoscan – утилита, создающая серьёзную вычислительную нагрузку в процессе получения 3D-моделей из множества 2D-изображений. Алгоритм содержит 4 отдельных этапа, предъявляющих жёсткие требования либо к скорости памяти, либо к значению IPC (инструкций за такт), либо к числу ядер, либо даже к аппаратной поддержке OpenCL. Agisoft предоставила особую версию утилиты, которая использует заранее созданный скрипт, предполагающий преобразование 50 изображений шикарного дома в одну 3D-модель среднего качества. Выполнение теста на базе мощного персонального компьютера без графической подсистемы требует порядка 15-20 минут – с видеокартой процесс ускоряется. 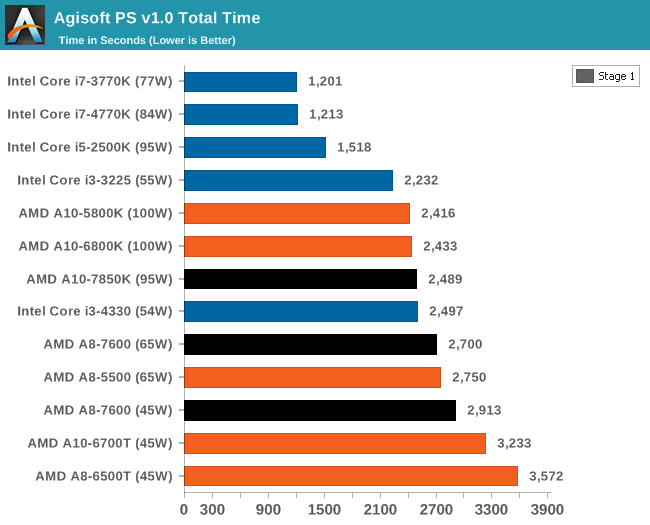 AMD уступает по общему времени исполнения из-за отсутствия полноценных ядер и частичного акцента алгоритма на однопоточную производительность. 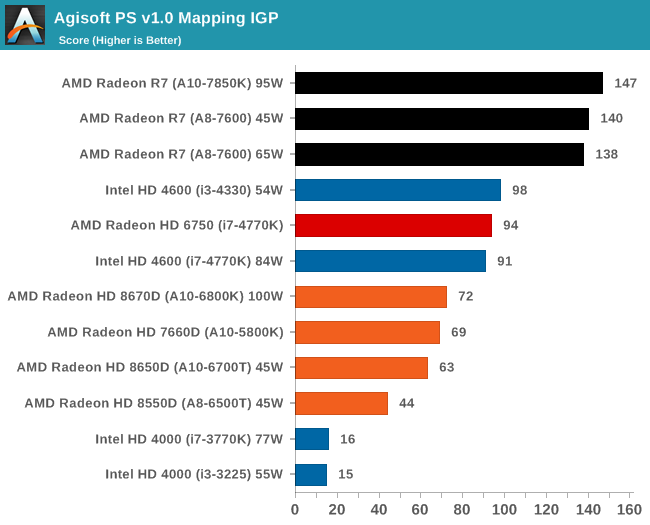 Второй этап позволяет задействовать ресурсы встроенного в APU видео, и в результате мощь современного APU AMD high-end класса затмевает все процессоры, участвующие в сегодняшнем тестировании. Перед нами как раз то, что сулит HSA – просто достижение подобного результата в большинстве применений потребует времени. 3D Particle Movement`3DPM – самостоятельный тест, использующий базовые алгоритмы с описанием движения в трехмерном пространстве вещества в процессе моделирования Броуновского движения с оценкой скорости выполнения алгоритмов. Высокая производительность вычислений с плавающей запятой, а также как можно большая частота и IPC – вот ключевые факторы победы в однопоточном режиме. Многоядерный режим, напротив, благоволит численному превосходству ядер. Как видно из результатов, AMD всё так же страдает от слабой производительности в вычислениях с плавающей запятой. 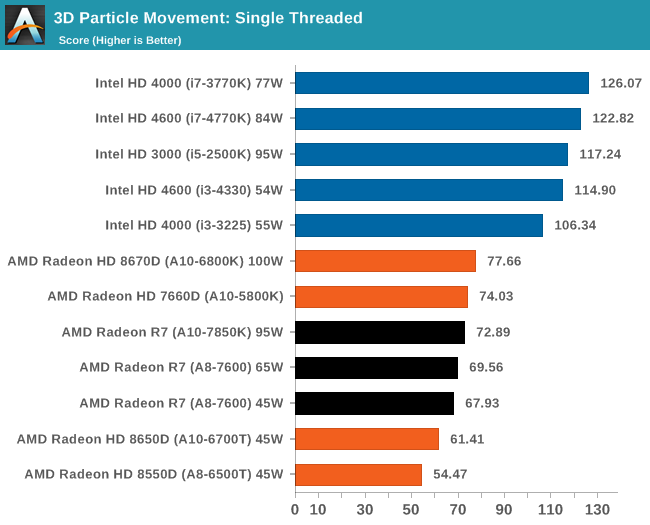 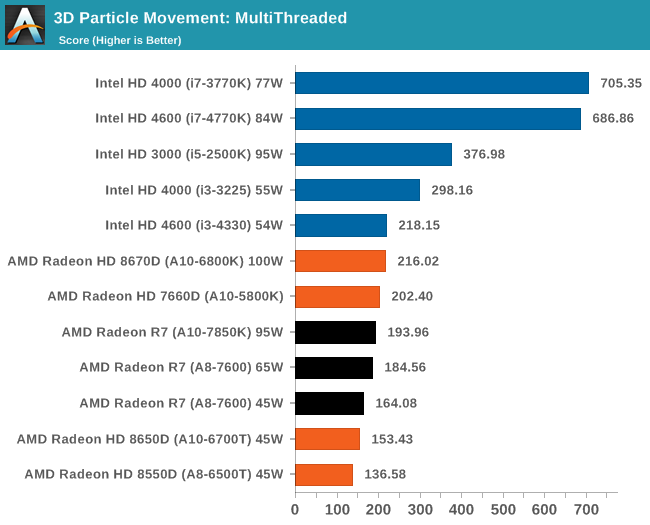 WinRAR 5.01WinRAR 2013 года тоже подвергся обновлению до версии, актуальной на начало 2014 года. Сжимается массив из 2867-ми мелких файлов, сгруппированных в 320 папок общим объемом 1,52 Гб. 95% этих файлов – типичные для веб-сайтов файлы небольшого размера; остальное – составляющие 90% всего объема небольшие, продолжительностью 30 секунд файлы с видео разрешением 720р. 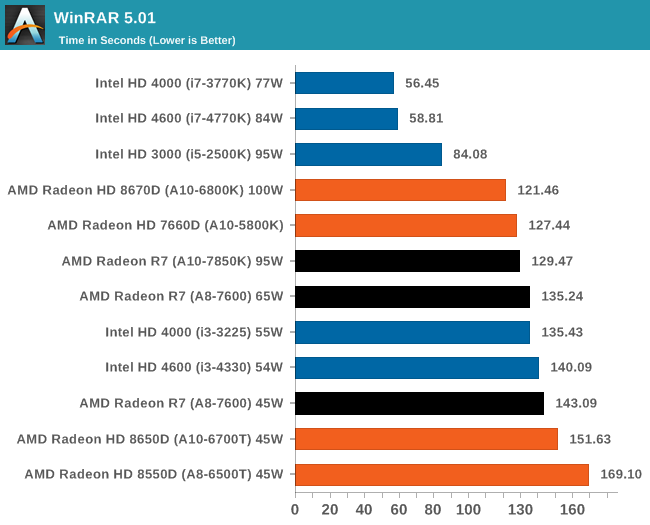 WinRAR предпочитает высокий IPC в процессорах Intel, поэтому даже немолодой Core i5-2500K показал себя с лучшей стороны. При этом 45-ваттный APU А8-7600 не покидает пределов поля боя с главным конкурентом из стана Intel. FastStone Image Viewer 4.9FastStone, подобно WinRAR, обновлен до актуальной на начало 2014 года версии. FastStone, в частности, используется для быстрого или пакетного редактирования изображений, включая такие операции, как изменение размера, корректировка цвета, обрезка. Массив из 170-ти разноформатных и разноразмерных изображений конвертируется в файлы с разрешением .gif с сохранением исходного соотношения сторон. Так как в данном сценарии FastStone не использует многопоточность, преимущество зачастую оказывается на стороне однопоточного режима, что и обуславливает выигрышное положение Intel. 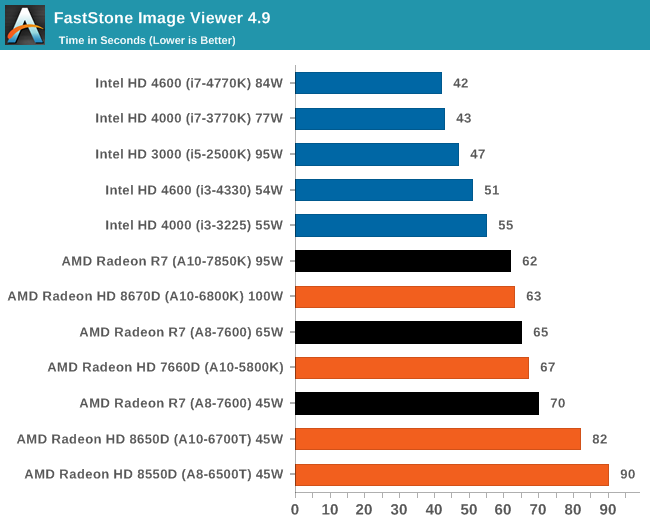 Xilisoft Video Converter 7Программный пакет XVC и методика тестирования также подверглись обновлению и теперь предполагают конвертацию в поддерживаемый Apple iPod формат двух видеофайлов – 10-минутного клипа с разрешением Double UHD (3840x4320) и DVD-рипа с разрешением 640x266 длительностью 2 ч 20 мин. Причина проста: когда размер кадра позволяет ему полностью поместиться в память, алгоритм обработки с большей вероятностью сможет «раскидать» нагрузку по потокам, способствуя ускорению процесса обработки видео. Поскольку XVC поддерживает аппаратное ускорение за счёт CUDA и AMD APP, результаты представлены и с учётом этой поддержки на GPU (если таковая имеется), и без неё. В случае с массивными кадрами пользы от встроенного в Kaveri видео немного, а вот для более «скромных» кадров поддержка AMD APP не проходит даром. Приводится время (в секундах), затрачиваемое на кодировку.  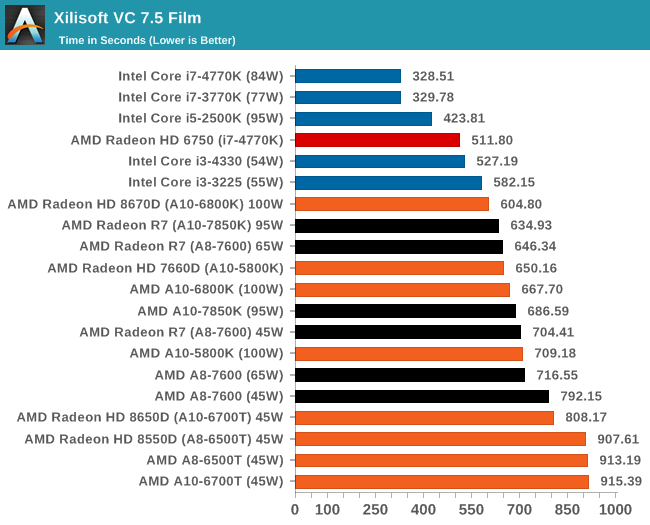 HandBrake v0.9.9В HandBrake берутся те же файлы, но с учётом формата на выходе, предлагаемого по умолчанию. Как следует из результатов (кадр/сек), в центре внимания Handbrake многоядерность, многопоточность и высокая частота работы ядра. 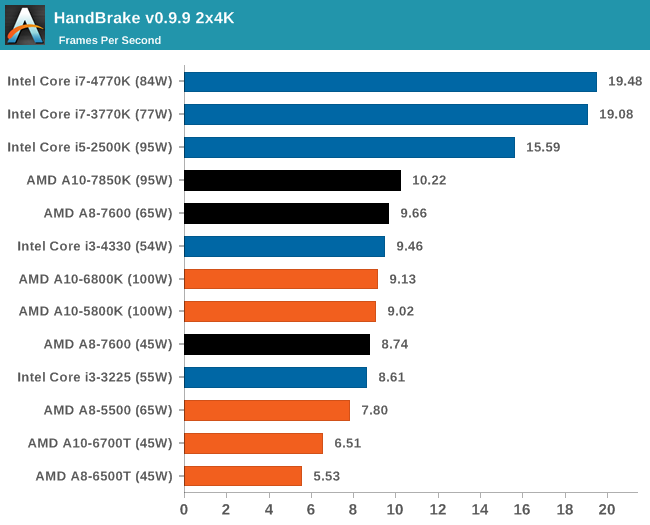 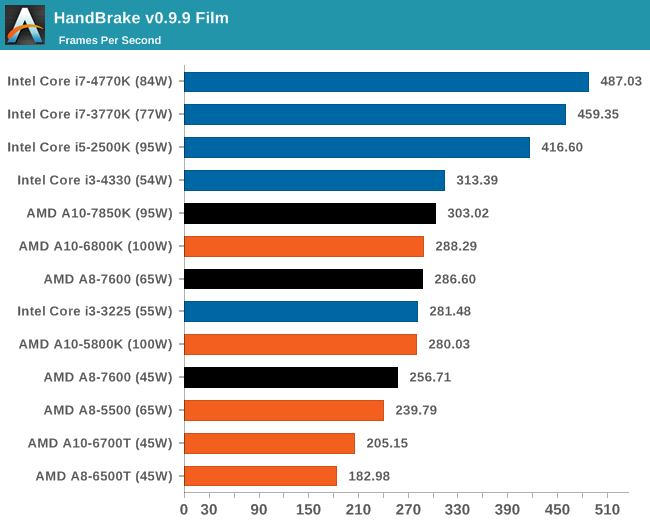 Adobe After Effects 6Программный пакет After Effects от компании Adobe, позволяющий работать с цифровыми динамичными изображениями, визуальными эффектами и композициями, используется в постобработке при подготовке фильмов и телепрограмм. В рамках данного теста рабочая сцена, взятая с форума After Effects, использовалась в качестве основы с учётом конкретных условий тестирования для достижения повторяемости результатов. Представленные результаты характеризуют скорость генерации 152 кадров в рамках единой сцены исключительно средствами CPU. 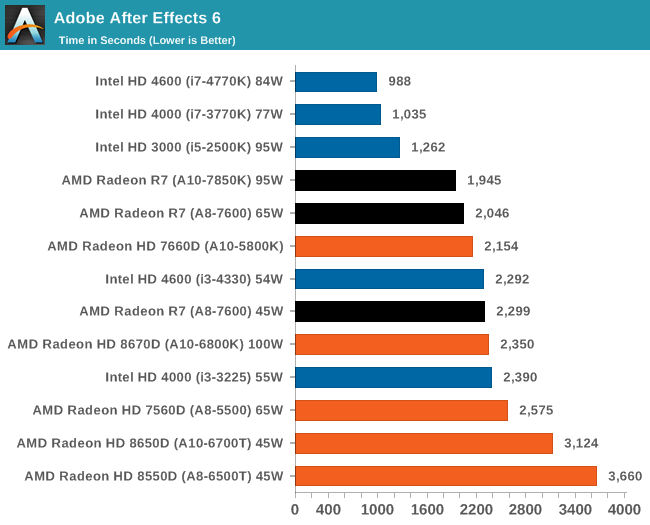 7-Zip 9.2Open-source архиватор 7-Zip – популярный инструмент для облегчения операций с множеством файлов, включая их передачу. Приводятся результаты для встроенного в 7-Zip бенчмарка. 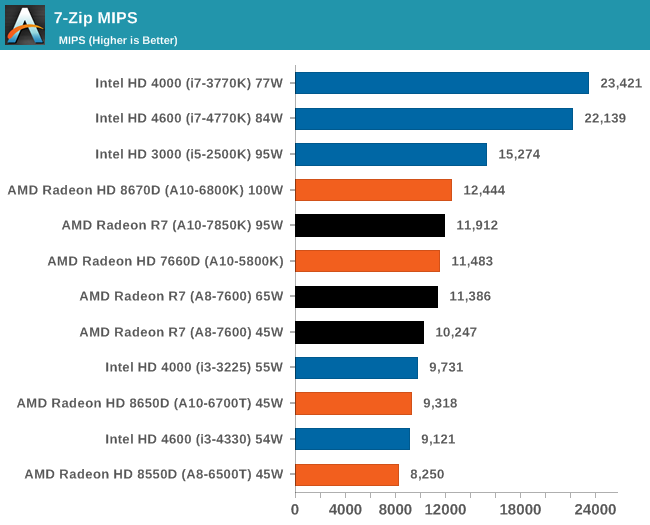 PovRay 3.7PovRay традиционно любит многопоточность, мегагерцы и IPC. Используется штатный для PovRay 3.7 бенчмарк. 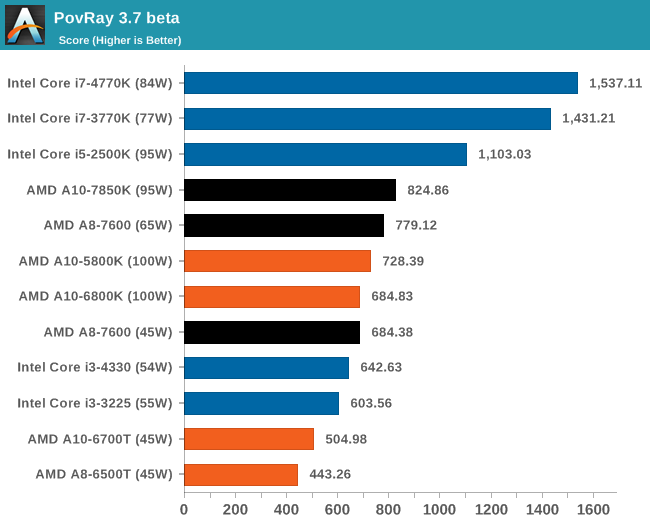 TrueCrypt 7.1a& |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Источник: www.anandtech.com/


