Каталог
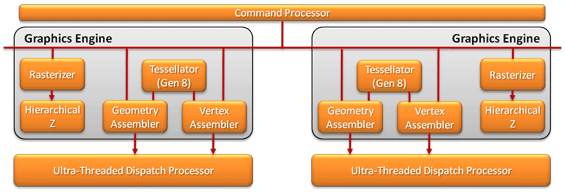
Cayman: новые горизонты GPGPU для AMDМы уже описали, каким образом переход от VLIW5 к VLIW4 должен сам собой улучшить общее математическое быстродействие: «узкие» SPU проще использовать полностью, скорость FP64 теперь соответствует 1/4 FP32, экономия площади позволила разместить дополнительные модули SIMD. Но так как Cayman позиционируется AMD как чип, который должен открыть для компании новую эру вычислений GPGPU и откусить значимый кусок пирога NVIDIA, потребовались более утонченные средства, чем просто перегруппированные шейдерные процессоры. Первая из причин, по которой VLIW4 является серьезной угрозой для Fermi, является асинхронное распределение задач, понятие, которое хорошо говорит само за себя. Здесь позволим себе напомнить о Fermi вновь, потому как именно с этой архитектурой NVIDIA сделала возможным одновременный запуск множественных параллельных ядер. В свою очередь, AMD воспользовалась удачной идеей конкурента, однако пошла в реализации еще дальше. Ограничение дизайна NVIDIA заключается в том, что хотя Fermi и способен запускать несколько ядер одновременно, все они должны быть приняты на обработку от одной нити команд CPU. Независимые потоки/приложения не могут просто так раздельно передавать ядра и запускать их параллельно, GPU для отработки подобной ситуации требуется переключение контекста. С внедрением асинхронного распределения задач AMD решает эту проблему; Cayman способен запускать независимые нити/приложения параллельно. По крайней мере, теоретически это должно дать AMD существенное преимущество в подобного рода ситуациях, так как смена контекста не является «дешевой» операцией с точки зрения потребления ресурсов. Преимущество это может быть столь значительно, что способно нивелировать имеющееся опережение GeForce.  На фундаментальном уровне асинхронное распределение достигается путем «утаивания» GPU определенной информации о своем реальном состоянии от приложения и ядер, что, по сути, представляет собой некий вариант виртуализации ресурсов графического процессора. Каждому ядру представляется, что оно запущено на выделенном GPU, имеет собственную очередь команд и адресное пространство. На самом же деле, вся работа по распределению разноплановой нагрузки ложится на процессор и драйверы. Хотя такая система сложнее в реализации, она дает ощутимый выигрыш в быстродействии по сравнению с применяемым NVIDIA принципом переключения контекстов. Обратная сторона данной технологии заключается в необходимости программной поддержки со стороны API. К сожалению, в текущей реализации единого стандарта DirectCompute 11 она не поддерживается, так что в ближайшее время асинхронное распределение будет доступно в качестве расширения OpenCL. Прочие улучшения, проделанные AMD, направлены на улучшение производительности памяти и кэша. Хотя базовая архитектура остается без изменений, некоторые мелочи могут положительным образом влиять на затрачиваемое на вычисления время. Так, локальные хранилища данных (Local Data Store, LDS), подключенные к SIMD, отныне соединены с VRAM напрямую, и выборки из памяти теперь могут попадать в них, минуя иерархию кэш-памяти и глобальное хранилище данных (Global Data Store, GDS). Кроме того, в Cayman был добавлен второй движок DMA, улучшающий показатели чтения и записи, а также дающий возможность параллельного запуска двух этих процессов в каждом направлении. Наконец, было несколько ускорено чтение из шейдерных процессоров; в отличие от Cypress, Cayman может объединять несколько запросов и сокращать число операций. Отметим, что, так как данный материал посвящен главным образом линейке Radeon HD 6900, мы не стали подробно останавливаться на всех мелочах новой архитектуры. Они будут интересны главным образом профессионалам, покупателям Firestream, и не окажут значимого влияния на решение о выборе игровой видеокарты. [N6-Улучшение работы с примитивами: двойной графический движок и новые ROP] Похоже, что AMD приняла комментарии NVIDIA по поводу геометрической производительности современных GPU близко к сердцу. Вместе с обозначением своей позиции по данному вопросу с релизом серии 6800, в компании продолжали работать над увеличением быстродействия блоков геометрии для будущих решений. В результате, фиксированный графический движок (Graphics Engine) был значительно улучшен в Cayman. До Cypress, в чипах AMD присутствовал единственный графический движок, включающий в себя каждый из следующих необходимых модулей в одном экземпляре: иерархический z-буфер и блок растеризации, трансляторы геометрии и вершин, а так же тесселятор. В RV870 AMD удвоила z-буфер и модуль растеризации, что позволило за такт обрабатывать до 32 пикселей против 16 ранее. Тем не менее, хотя инженеры частично усовершенствовали графический движок, не все его части были улучшены. Так, по примитивам никаких изменений внесено не было, и комплекс мог выдавать только одну единицу за такт, что соответствовало стандартам на то время.
В 2010 году с запуском Fermi NVIDIA значительно подняла планку по данному параметру. Функции растеризации в чипах GeForce переместились в GPC, и в GF100/GF110 NV довела количество выдаваемых за такт примитивов до числа этих самых графических кластеров. В рамках одного поколения модернизация была просто революционной, особенно на фоне вялотекущих изменений за многие годы до этого. В Cayman AMD предприняла попытку сократить отставание от NVIDIA в вопросах геометрии, улучшив собственные показатели работы с примитивами. Правда, о столь впечатляющем приросте говорить не приходится. При создании Cayman, нетронутые ранее в Cypress оставшиеся части Graphics Engine были удвоены и разнесены — во флагманском видеопроцессоре AMD отныне имеется два раздельных графических движка, каждый из которых наделен базовой функциональностью и способен выдавать 1 примитив за такт. В сумме это и дает уровень, вдвое превосходящий возможности Cypress. Правда, во столько же раз топовый чип семейства Southern Islands уступает и high-end решениям NVIDIA.
Как это могут подтвердить коллеги из NVIDIA, разделение растеризации и тесселяции оказалось не такой простой задачей. Трудность у команды AMD возникла на этапе создания попросту отсутствующего ранее механизма балансировки нагрузки между модулями для максимально полной загрузки их работой. По словам представителей графического подразделения AMD, решить этот вопрос удалось очень элегантно, и дальнейшее наращивание мощности части чипа, ответственной за геометрию, будет происходить прозрачно и без дополнительных доработок. С этой позиции Radeon HD находится в выигрыше, так как NV необходимо следить за отношениями GPC/SM/SP при модернизации своих чипов. В конечном счете, все эти действия сами по себе не слишком важны на данный момент; фактически, они являются только подготовительными этапами для увеличения производительности столь важной для DX11 тесселяции. В аппаратном блоке тесселяции 7ого поколения скорость при малых факторах уже была повышена, так как в этом случае ограничительным фактором были сами возможности тесселяции Cypress. Но при высоких факторах проблемой был именно графический движок, который «захлебывался» с поступлением на вход большего числа примитивов, чем он способен обработать. Теперь, когда в Cayman имеется два выделенных Graphics Engine, предел по растеризации двух примитивов за такт перестает быть ограничителем. Сам факт наличия двух тесселяторов, аналогичных седьмому поколению Barts, является весомым преимуществом Cayman. Однако такую сложную структуру необходимо обеспечивать и соответствующей «обвязкой», так как быстроты геометрического движка все равно может не хватать, а, значит, промежуточные данные должны где-то храниться, ожидая свой черед на обработку. К сожалению, величины кэшей в Cayman остались неизменными, а это означает, что на старое хранилище данных может приходиться втрое больше данных. Было принято решение размещать их в набортной видеопамяти. Не самое оптимальное решение с точки зрения быстродействия, но оно в любом случае лучше, чем ожидание всего конвейера рендеринга окончания процессов растеризации.
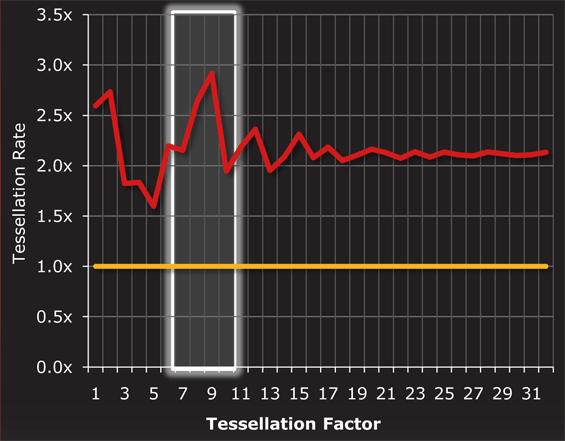
В общем и целом, на одной тактовой частоте тесселяция в Cayman происходит от полутора до трех раз эффективнее, чем в Cypress. В ситуациях, где AMD уже улучшила быстродействие тесселяции в Barts, может достигаться трехкратное преимущество (низкие факторы), тогда как при коэффициенте 5 разница составляет минимальные полтора раза. В среднем производительность возросла вдвое, что хорошо коррелируется с удвоением графических движков. Кроме того, тесселяция является одной из причин, по которым AMD серьезно переработала модули ROP. Результат работы тесселятора — заметно более детализированная геометрия моделей, выражающаяся в большом количестве мелких треугольников, которые очень сложно обрабатывать ROP при выполнении MSAA. Общее количество ROP осталось прежним — 32 штуки, но определенные операции они теперь исполняют существенно быстрее. В обоих случаях расчетов подписанных и неподписанных нормированных INT16, разработчики могут использовать преимущества двукратного ускорения. С FP32 Cayman работает от 2 до 4 раз быстрее в зависимости от сценария. Наконец, похожим на чтение из регистров шейдерных процессоров образом, для ROP была добавлена возможность объединения запросов на запись и сокращение их общего числа. [N7-Определяем TDP по-новому: PowerTune] Одним из бенчмарков, используемых нами в тестированиях на постоянной основе, является FurMark от oZone3D. Эта утилита предназначена для того, чтобы вывести видеокарты в режим максимального энергопотребления. «Волосатый бублик», как эту программу часто называют энтузиасты, способен генерировать такую нагрузку, которая практически недостижима ни в реальных играх, ни в GPGPU приложениях. Нужно это для того, чтобы определить, сколько энергии требует плата, до какой температуры разогревается GPU, и насколько громко работает система охлаждения в самом худшем варианте развития событий. Тот факт, что это ПО столь грубо обращается с картами, демонстрируя нетипичные для реальных игр результаты, стал причиной того что оба ведущих производителя окрестили FurMark «энергетическим вирусом» и начали встраивать разнообразные защиты от подобных утилит.  Откровенно говоря, вся эта история с FurMark является не причиной, а следствием большой проблемы; здесь мы говорим о TDP. Конечно, прямое сравнение здесь не совсем корректно, но центральные процессоры с максимальным TDP порядка 140 Вт являются просто эталонами экономичности по сравнению с монструозными графическими картами. Спецификации стандарта ATX определяют максимальное энергопотребление PCI-Express устройств в 300 Вт, в наших тестах эта граница зачастую преодолевается при запуске FurMark. Еще сложнее обстоит дело с мобильными ПК или компьютерами класса «все-в-одном», где ограничения свободного пространства и/или емкости батареи вместе с необходимостью использования компактных систем охлаждения для рассеивания тепла и вовсе ставят GPU в жесткие рамки. По этим причинам все платы должны соответствовать определенному тепловому пакету TDP. Скажем, чтобы уложиться в рамки 300 Вт, AMD пришлось снизить для Radeon HD 5970 частоты, хотя были использованы полноценные чипы 5870. По этой же причине в ноутбуках нередко можно встретить графические карты, обрезанные по числу функциональных блоков и с минимальными частотами. Хотя мы не раз видели, что платы AMD и NVIDIA превышали заявленные значения TDP в FurMark, разница между номинальным и фактическим значением никогда не была криминальной. Ведь хотя производители давно отошли от практики приравнивания TDP к максимальному энергопотреблению устройства, постоянное превышение этого усредненного значения на значительную величину ведет к перегревам и возможному механическому повреждению оборудования. Именно из-за подобных FurMark программ разработчикам приходится создавать некоторый запас прочности для GPU, тем самым несколько снижая их производительности. В Call of Duty, Crysis и The Sims 3 проблем при более высоких частотах практически гарантированно не возникло бы на большинстве видеокарт, но необходимость перестраховки определяется по худшему из сценариев. Все это подводит нас к концепции, которая уже реализована в современных центральных процессорах в виде технологий Turbo Boost от Intel и Turbo Core от AMD. Очевидно, что в зависимости от типа нагрузки в большей или меньшей степени загружаются различные блоки GPU, определяя при этом и TDP. В частности, при некачественной оптимизации GPU может практически простаивать, а плата при этом будет потреблять совсем немного энергии. Чем не повод, чтобы поднять частоты и напряжения, улучшив производительность самым простым путем? Напротив, в FurMark и прочих «тяжелых» программах частоты можно снижать относительно базовой планки, которую в случае с динамическим регулированием можно установить выше, чем это обычно делается с учетом необходимости оставить запас по TDP. 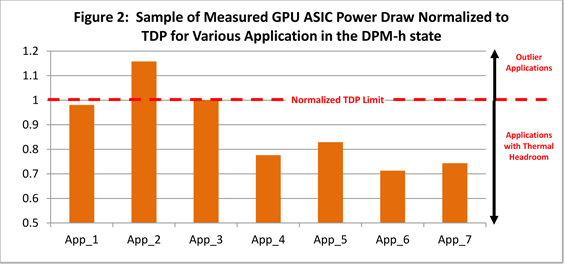 Получается, что динамическое изменение частот (и, возможно, напряжения) является идеальным способом поддержания максимального быстродействия платы в зависимости от характера нагрузки; пониженная тактовая частота поможет сократить потребление энергии и выделение тепла в ресурсоемких играх, а увеличенные значения принесут дополнительные FPS в легких приложениях без выхода за рамки TDP. В общем-то, после удачной реализации в CPU этих принципов, которые помогли Intel и AMD не только увеличить среднюю производительность, но и соблюсти баланс между одно- и многопоточными программами с разными требованиями к числу ядер, приход подобной схемы в GPU был только вопросом времени. Месяцем ранее мы уже видели первые шаги в этом направлении со стороны NVIDIA; в серии GTX 500 компания применила специальные чипы для мониторинга энергопотребления, на основании показаний которых драйвер отдавал команду на снижение частот при запуске FurMark и OCCT. Правда, на этих двух программах и одностороннем процессе NVIDIA остановилась. AMD же разработала для Cayman и 6900 существенно более продвинутый алгоритм, получивший название PowerTune. Технология PowerTune представляет собой механизм сдерживания энергопотребления GPU, стремящийся удержать аппетиты чипа в заранее определенных рамках. По сути, работает он по обратному к Turbo принципу. Вместо того чтобы принимать за базу низкую частоту, и поднимать ее более высокими множителями, как это сделано в процессорах, AMD установила изначально высокую частоту, которая понижается при превышении TDP. Так что, при работе в 3D чипы изначально настроены на максимально возможное быстродействие с высокими напряжениями и частотами, PowerTune же в реальном времени замедляет их при необходимости. Исполнение функциональности PowerTune достигается в два этапа. На первом происходит определение TDP продукта. В отличие от NVIDIA, специальных чипов для мониторинга энергопотребления AMD не использует. Тем самым, удается сэкономить на комплектующих и не усложнять дополнительно разводку печатной платы. Вместо этого AMD определяет энергопотребление GPU по загрузке основных функциональных блоков чипа. Каждому из них присвоен определенный весовой коэффициент; общая сумма и позволяет приближенно говорить о загрузке чипа в целом. Точное уравнение AMD не приводит, но общий его вид соответствует следующему: Энергопотребление = ((загрузкаПотоковыхПроцессоров * весПП) + (загрузкаROP * весROP) + (использованиеПамяти * весПамяти)) * тактовая частота ядра В случае с Radeon HD 6970, TDP равняется 250 Вт, тогда как тактовая частота — 880 МГц. После того, как значение энергопотребления было получено, графический процессор может конфигурироваться на лету для того, чтобы не превосходить TDP. Под словом «конфигурировать» мы подразумеваем изменение только тактовой частоты, основанное на данных об энергопотреблении, обновляемых несколько раз в секунду. Пока аппетиты карты укладываются в 250 Вт значение, 6970 продолжает работать на 880 МГц. Как только же условие соответствия верхней границы теплового пакета перестает выполняться, частота снижается, чтобы вернуть плату в 250 Вт зону. На практике частота ядра и потребление энергии находятся в нелинейной зависимости, поэтому PowerTune может замедлить GPU на совсем небольшую величину, чтобы успешно выполнить свою задачу. К сожалению, частота памяти и напряжения VCore/VRAM остаются без какого-либо контроля (только со стороны фиксированных профилей PowerPlay), так что меняется только тактовая частота ядра. Вероятно, с повсеместным внедрением PowerTune фундаментальным образом изменится методика, по которой мы оцениваем потребление энергии графическими картами AMD. С учетом работы PowerTune получается, что заявленное TDP платы в действительности соответствует реальным энергетическим показателям. Основное преимущество PT заключается в отсутствии привязанности к какой-либо программе или игре; технология просто работает везде, не позволяя GPU превзойти TDP. Вместе с тем следует понимать, что иногда энергопотребление в игре может быть существенно ниже числа, указанного в качестве значения теплового пакета, так что в любом случае будет существовать худший и средний сценарии для видеокарты, пусть разница между ними и сократится. В результате, демонстрируемая продуктами производительность может значительно отличаться от теоретической. Здесь мы вновь обратимся за примером в мир центральных процессоров, где быстродействие CPU зависит не только от условного значения TFLOP, скорости кэша и частот, но и от множества других факторов. Установленное производителем значение TDP и то, насколько часто при работе под нагрузкой карта превышает его, отныне является важным фактором в «формуле скорости». Похожим образом на реализацию потенциала центральных процессоров влияет и качество систем охлаждения, благодаря которым становится возможным достижение более высоких показателей в Turbo-режимах. По крайней мере, для GPU AMD на первый план теперь выходит соотношение производительности на Ватт; максимум, на который карта способна в рамках определенного для нее теплового пакета, оказывается зависим не только от тактовых частот, как это было раньше. Наверняка читателю интересно, какого же реальное влияние PowerTune на скоростные показатели Radeon HD 6970 и 6950. Ответ может показаться удивительным, но на данный момент мы можем констатировать, что оно практически отсутствует. Чтобы продемонстрировать зафиксированные нами изменения, представим вашему вниманию список игр и приложений из нашего тестового пакета. Из более чем дюжины проведенных бенчмарков действие PowerTune сказалось лишь на двух: FurMark (что полностью ожидаемо) и Метро 2033. Правда, разница в поведении 6970 в этих ситуациях была колоссальна.
В случае с Метро, средняя тактовая частота ядра равнялась 850 МГц; 95% времени графический процессор отработал на 880 МГц, и лишь в паре моментов случались кратковременные сбросы до 700 МГц. Напротив, известный своим горячим нравом FurMark вынудил PowerTune снижать частоты до 600 МГц, что соответствует 30% сокращению. В результате, падение производительности в FurMark было довольно значимым, а вот на Метро 2033 внедрение PT в 6970 практически никак не сказалось. Докажем данное утверждение:
Как вы можете видеть, разница в среднем не превышает 0.5 кадра в секунду, что и вовсе укладывается в погрешность измерений. На любой тест, запускаемый нами на 6970 и 6950, стандартные настройки PowerTune не оказывали какого-либо видимого влияния. Это позволяет сделать вывод, что выраженных недостатков при использовании в настольных ПК PowerTune не имеет. В итоге мы имеем механизм, работающий по принципу отрицательной обратной связи, против Turbo, где используется положительная обратная связь. Без разгона лучшие результаты 6970 показывает на своей штатной частоте в 880 МГц безо всякого вмешательства PowerTune, тогда как Turbo добавляет скорости, если это возможно. Субъективно эти подходы воспринимаются по-разному, так как первый уменьшает производительность относительно базового уровня, а второй «дарит» дополнительное быстродействие. Сложно четко выявить, какой из них лучше, но с учетом наличия различных профилей для 2D, экономичного и полнофункционального 3D у PowerPlay, эффективность PowerTune не вызывает сомнений. Заметим, что хотя мы рассмотрели PowerTune с точки зрений использования в десктопных компьютерах, прочие, возможно даже более важные сферы применения, были оставлены без внимания. На презентации AMD не раз упоминала о ценности PowerTune в контексте мобильных ПК, так как именно в портативных устройствах наиболее важен баланс быстродействия, энергопотребления и тепловыделения. Кроме того, не последнюю роль ноутбуки играют и в бизнесе компании, так как доля подобных устройств неуклонно растет. А в данном секторе рынка наличие PT не только означает гарантированный уровень TDP для мобильных графических чипов, но и возможность установки более высоких штатных частот для требовательных игр. Все это должно увеличить популярность Mobility Radeon HD. Скорее всего, важность PowerTune не будет оценена в 2011 году (чего стоит хотя бы приведенные выше показатели серии 6900), но сомневаться в том, что за этой технологией будущее, не стоит. Впрочем, одно возможное исключение мы можем привести уже сейчас — речь идет о 6990 (Antilles). В свое время Radeon HD 5970 оказался в довольно-таки интересной ситуации. Эта плата была (и, вообще говоря, остается) одним из самых быстрых ускорителей современности, однако в случае неработоспособности CrossFire она работала медленнее 5870. Так происходило потому, что для того, чтобы уложиться в 300 Вт TDP, AMD пришлось снизить тактовые частоты чипа и памяти по сравнению с полноценным одиночным Radeon HD 5870. В прошлом поколении 4870X2 следовала другому пути, так как этот двухголовый флагман являлся настоящей «склейкой» двух HD 4870, и ни при каких условиях не уступал этим GPU. Теперь, благодаря PowerTune, сценарий, имевший место с 5970, не повторится на 6990: гипотетический 6970X2 будет обладать равными с 6970 частотами, а PT проследит за энергопотреблением, и в случае необходимости снизит частоты для соответствия TDP в 300 Ватт. Получается, что даже в худшей ситуации 6990 не проиграет 6970, и на компромиссы владельцам Antilles идти не придется. В то же время, параметры PowerTune не задаются AMD жестко; их можно изменять в контрольной панели Overdrive. [N8-Настройка PowerTune] Хотя цель, для которой создавалась PowerTune, является благой, разработчики AMD прекрасно понимали, что не всем пользователям эта технология нужна. По этой причине в панель управления Overdrive были добавлены настройки для контроля PT, с помощью которых дозволено изменять порог срабатывания защиты на 20% в обе стороны.  Начнем наши эксперименты с увеличения предела для PowerTune. Заметим, что в целях обеспечения механической/тепловой защиты дорогостоящих видеокарт, полностью этот механизм отключить нельзя. В случае с 6970, наличие слайдера, позволяющего двадцатипроцентные манипуляции с лимитом TDP для PT, означает возможность смещения границы от 200 Вт до 300 Вт (официального предела спецификаций ATX). Результат увеличения предела срабатывания PowerTune будет зависеть от того, насколько далеко вы отодвинете стандартную границу. Небольшое увеличение приведет к некоторому приросту производительности в играх/приложениях, сдерживаемых PT ранее, тогда как достижение 20% максимума практически отключит PowerTune для стандартных частот и напряжений. Мы уже выяснили, что с границей по умолчанию в 250 Вт, PowerTune оказывает влияние только на FurMark и Метро 2033, причем игровое быстродействие практически не страдает. Помня об этом, мы увеличили лимит для PowerTune до 300 Вт и вновь провели замеры энергопотребления и температурного режима.
Как и ожидалось, температура и энергопотребление в FurMark заметно увеличились при установке границы PowerTune на 300 Вт. В данном случае PowerTune никоим образом не ограничивала FurMark, и ядро 6970 все время работало на 880 МГц. Общее энергопотребление системы при этом возросло на 60 Вт, что соответствует на 46.6% более быстрой работе GPU. Естественно, раз «свободу» получил даже FurMark, Метро 2033 также хватило пространства расправить крылья. Впрочем, мы уже отмечали, что хотя PT и давала знать о себе при тестировании Метро, влияние на число FPS она практически не оказывала. Были сделаны и иные интересные наблюдения, касающиеся Crysis. Хотя в Warhead активности PowerTune нами замечено не было, в 300 Вт режиме потребление мощности Radeon возросло на 15 Вт; производительность при этом никоим образом не изменилась. Найти разумное объяснение данному феномену мы затрудняемся, так как изо всех доступных PowerTune инструментов имеется возможность управления одной лишь частотой ядра (не напряжением), а она не изменялась при переходе от 250 Вт к 300 Вт режиму. Впрочем, это не влияет на логичный вывод из проведенного исследования, что для работы на штатных частотах смысла поднимать границу для PowerTune нет. Это подводит нас к вопросу разгона. Из-за временных ограничений на подготовку материала, мы не смогли исследовать вопрос оверклокинга серии 6900 всесторонне. Впрочем, так как в уравнении PowerTune тактовые частоты играют важную роль, и без дополнительных изысканий становится понятно, что необходимо настраивать PowerTune для предотвращения блокировки разгона. Ведь на стандартных установках эта технология будет автоматически понижать частоты для соответствия типичному тепловыделению в 250 Вт вне зависимости от того, какие настройки GPU вы сделаете. Хорошие новости для оверклокеров состоят в том, что хотя референсные платы AMD имеют 20% предел для увеличения TDP, партнеры будут давать пользователям больше свободы в своих изделиях. Так что, в сериях Gigabyte SOC, MSI Lightning или ASUS Matrix не стоит бояться столкнуться с искусственным пределом разгона из-за PowerTune. Остался неисследованным вопрос понижения порога срабатывания PowerTune. Хотя обычно мы рассматриваем все с позиции «чем больше, тем лучше», определенная логика в уменьшении энергопотребления видеокарты есть. Пользуясь стандартными методами и не корректируя частоты напрямую, можно добиться снижения потребления энергии и без PowerTune с помощью вертикальной синхронизации. Включение VSync существенно ограничивает производительность видеокарты, практически уменьшая число выдаваемых кадров в секунду вдвое. У этой технологии есть свои сторонники и противники — первые не могут спокойно наслаждаться 3D-графикой с артефактами «разрыва» изображения при быстрых поворотах камеры, вторые сетуют на пропуск кадров и увеличение задержек там, где не поддерживается тройная буферизации. Используя PowerTune же можно снизить энергопотребление очень просто без дополнительных «телодвижений». Как и в случае с повышением до 300 Вт, мы провели замеры показателей 6970 с понижением TDP до 200 Вт.
Все функционирует так, как и заявлено производителем. Довольно интересно выглядит равенство потребляемой мощности в созданном режиме между Crysis и FurMark. Это говорит о том, что при стандартных частотах отнюдь не все блоки видеокарты загружаются полностью, а вот уменьшение верхней границы TDP уравнивает отдачу Radeon HD 6970 в одной из требовательнейших игр и самом прожорливом приложении. Хотя нельзя назвать 6970 бесшумной в таком режиме, при 200 Вт эта карта работает ощутимо тише стандартных для PowerTune 250 Ватт. К сожалению, это уже напрямую отражается и на быстродействии графического процессора. Почти во всех играх мы зафиксировали сопоставимую с 20%-ной экономией энергии потерю производительности.
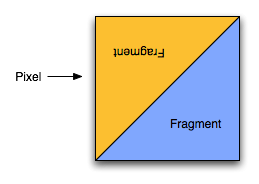
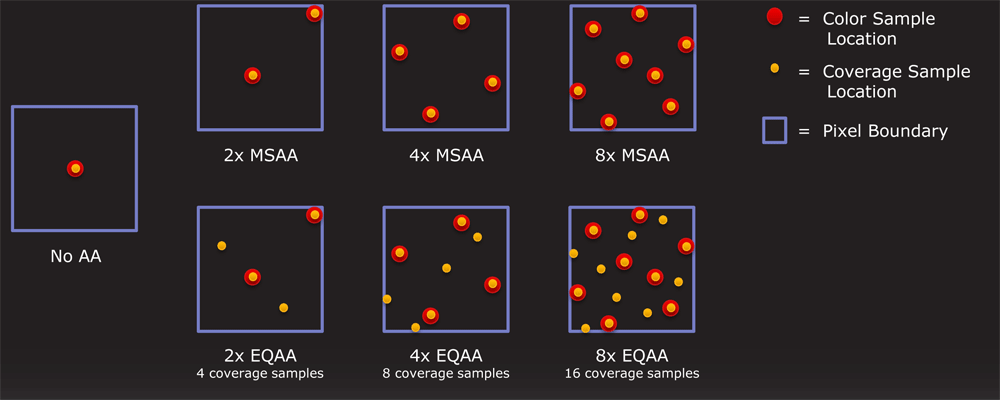
В Crysis можно говорить о 75%-80% показателях от полной силы 6970 при установке PT в 200 Вт. Впрочем, точное значение зависит от характера нагрузки того или иного приложения. [N9-Новый режим антиалиасинга: Enhanced Quality AA] Вместе с серией 6800 AMD представила новый тип экономичного сглаживания Morphological Anti-Aliasing (MLAA), который являлся несложным пост-процессинговым фильтром. Среди достоинств такого подхода можно выделить работоспособность в широком наборе игр, независимость от используемых API и малое снижение быстродействия. Но на этом AMD не остановилась; компания разрабатывала для 6900 еще один режим антиалиасинга. Новинку окрестили Enhanced Quality Anti-Aliasing (EQAA), или антиалиасинг повышенного качества. Чтобы получить представление о том, что это за техника сглаживания, достаточно вспомнить Coverage Sample Anti-Aliasing (CSAA), созданный инженерами NVIDIA для GeForce 8800 GTX, так как практически эти технологии идентичны. В случае с традиционным MSAA, пикселю, покрытому двумя или более треугольниками/ фрагментами, необходимо 2, 4 или 8 выборок субпикселей для достижения финального результата. В процессе фиксируется и временно сохраняется цвет треугольников, а также значение их Z/глубины, после чего полученные данные смешиваются для определения результирующего пикселя. Этот механизм отлично работает для решения проблемы «лесенок» на краях полигонов, причем требует заметно меньше ресурсов, чем настоящий суперсемплинг. Впрочем, он все равно является относительно дорогим. Сбор и хранение Z-координат вместе со значениями цветности требуют не только дополнительного объема памяти, но и резерва по пропускной способности. Впрочем, хотя существует минимально достаточное количество выборок для определения цветов задействованных треугольников, не всегда их число велико. В большинстве случаев минимального набора цвета/Z-координат достаточно, и сложность заключается в оптимальном смешивании значений цветов.
Здесь и приходят на помощь методы, подобные EQAA; в некотором роде они являются компромиссными, а суть их в следующем. Хотя полноценные операции с парой «цвет-Z» требуют немало ресурсов, простая проверка на покрытие треугольником субпикселя практически «бесплатна». Получается, что можно повысить качество сглаживания в том случае, если использовать минимально-достаточную выборку координат и цветов вместе с дополнительной проверкой на покрытие. Это позволит более точно определить, какой процент пикселя покрывается конкретным полигоном, что, в свою очередь, приведет к лучшему смешиванию цветов. Например, при «чистом» 4x MSAA величина покрытия может быть определена дискретно как 0/25/50/75/100 процентов. С 4x EQAA, в котором используется 4 выборки цвета и дополнительные 4 семпла покрытия пикселя, точность повышается, так как параметры смешивания могут быть определены уже на основании более диверсифицированного диапазона 0/12/25/37/50/62/75/87/100%. Отметим, что такого же результата в случае с MSAA можно добиться только в режиме 8x. Согласитесь — довольно привлекательно получать сравнимое с затратным 8x MSAA качество при лишь немного превышающей 4x MSAA стоимости.
Конечно, на практике все неидеально. Говорить о том, что 4x EQAA аналогично 8x MSAA можно только понимая, что речь идет о лучшем развитии событий. В худшем случае дополнительные выборки покрытия пикселя могут не принести вообще никакой пользы, и качество 4x EQAA не будет отличаться от 4x MSAA. Это зависит от конкретной игры, если даже не от конкретной ситуации и игровой сцены. В действительности CSAA/EQAA могут помочь немного улучшить результаты относительно MSAA при минимальном снижении скорости. Тогда как графические чипы NVIDIA умели делать выборки покрытия еще со времен G80, в решениях AMD эта возможность была ранее недоступна. Теперь же, с новыми блоками ROP и платы Radeon серии 6900 наконец-то стали поддерживать эту возможность. Как мы уже отмечали, за исключением разницы в названиях, реализация описанного механизма у AMD и NVIDIA практически идентична. Видеокарты обоих вендеров теперь способны делать независимые от пары «цвет-Z» выборки покрытия в зависимости от установленных настроек. Небольшое преимущество AMD заключается в том, что, как и в случае с прочими режимами сглаживания, компания дает разработчикам возможность использовать специфические, специально подобранные шаблоны для выборок. Как и в случае с CSAA от NVIDIA, EQAA AMD доступен в DirectX приложениях, а также может быть форсирован через драйвер.
В распоряжении пользователей AMD есть один режим, недоступный сторонникам NVIDIA, — 2xEQ, представляющий собой 2x MSAA + 2x выборки покрытия, тогда как NV может предложить типы 16x (4x MSAA + 12x выборок) и 32x (8x MSAA + 24x семпла). Отметим, что дополнительные выборки покрытия в случае с AMD также мало влияют на производительность, как и у NVIDIA. [N10-Знакомство с 6970 и 6950] Теперь, когда мы подробно рассказали о внутреннем устройстве чипов видеокарт серии 6900, давайте взглянем на самих виновниц торжества. Если вы знакомы с линейкой 6800, найти много общего между ее представителями и 6900 не составит труда. Внешне референсные карты AMD и вовсе похожи, используется полностью закрытый угловатый дизайн системы охлаждения. Интересно, что, как и в случае с парой GTX 580/570, 6970 и 6950 обладают единой печатной платой и кулером, так что сказанное об одной из сестер будет полностью соответствовать и другой. Напомним, что PCB 5850 была упрощена относительно 5870. Чтобы не проделывать двойную работу напрасно, будем использовать для обзора конструкции только 6970.
Длина 6970 практически аналогична 5870 и достигает 26.67 см. Покупатели, которым необходима более короткая видеокарта (например, как 5850), могут временно занять позицию ожидания, так как нестандартные решения партнеров AMD еще не подоспели, а референсная 6950, как нетрудно догадаться, также требует чуть больше 26.6 см пространства. Дополнительное питание флагманскому одночиповому Radeon обеспечивают два разъема PCIe 8 + 6 контактов, так как TDP 6970 в 250 Вт превосходит 225 Вт лимит комбинации 6 + 6 пин. Напротив, более экономичной 6950 с TDP в 200 Вт достаточно и такого упрощенного набора. Расположение разъемов на торце является плюсом и облегчает подключение.  Конечно, после снятия СО сразу становится понятно, насколько PCB 6970/6950 отличается от серии 6800. По центру виден графический процессор Cayman во всей своей красе 389 квадратных миллиметров, вокруг него заняли место восемь 2 Гбит чипов Hynix GDDR5. Согласно маркировке они предназначены для работы на эффективной частоте в 6 Гбит/с, т.е. на 0.5 Гбит/с больше прошитых в BIOS частот. Как и раньше, особая сложность в эксплуатации высокоскоростной GDDR5 заключается в проектировании соответствующей шины между GPU и чипами памяти. Определенного прогресса в этом направлении с 6900 AMD добилась, но, похоже, что преодоления барьера в 6 Гбит/с мы так и не увидим, по крайней мере, для 256-битных интерфейсов. По спецификациям, GDDR5 должна покорить даже 7 Гбит/с, но, с учетом возникших у AMD и NVIDIA сложностей с контроллерами, вряд ли на серийных видеокартах будут достигнуты такие показатели.  Говоря о системе охлаждения, можно заметить, что кулеры с испарительными камерами в этом году однозначно в моде. Для AMD использование подобных конструкций не в новинку, вспомним хотя бы недавний двухчиповый 5970. Но на одиночных платах Radeon HD радиаторы такого типа не встречались давно, со времен HD 2900. По сравнению с распространенными решениями на тепловых трубках, конструкция испарительной камеры позволяет более эффективно переносить тепло. К тому же, инженерам нет необходимости беспокоиться о том, как разместить выступающие части трубок. Воздушный поток через ребра радиатора обеспечивает радиальный вентилятор увеличенного по сравнению с 5870 диаметра. Это вполне понятная модернизация с учетом того, что 6970 должна быть однозначно более горячей, чем |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Источник: www.anandtech.com/