Каталог
Cayman: последняя жертва 32 нмВ статье по GPU Barts и серии 6800 мы уже затрагивали тот факт, что AMD рассчитывала использовать 32 нм производство, которое при росте числа транзисторов позволило бы получить более компактные кристаллы, которые бы стали основой для продуктов компании на 2011 год. Однако TSMC серьезно отстала от графика освоения сначала 40 нм, а затем и 32 нм литографии. Впоследствии компании пришлось и вовсе отказаться от своих планов на 32 нм нормы, так что при создании нового поколения Radeon HD, AMD осталась в заложниках 40 нм рамок. Так и не увидевший свет 32 нм предвестник Barts стал одним из ранних проектов, которые было решено реализовывать с использованием отработанных 40 нм технологий. Дело в том, что еще до того, как руководство TSMC объявило об отказе от 32 нм, стало понятно, что стоимость изготовления одного 32 нм транзистора превышала бы аналогичное значение для 40 нм даже несмотря на меньший физический размер элементов. Для видеокарт среднего класса 32 нм производство оказалось экономически нецелесообразным, так как норма прибыли была бы меньше желаемой AMD. Так что, Barts решено было проектировать по 40 нм стандартам. История Cayman развивалась по несколько иному сценарию. Данный чип изначально планировался как high-end GPU, и разница в себестоимости 32 нм и 40 нм версий не должна была играть значимую роль с учетом немалой наценки на топовые ускорители (это не говоря о профессиональных версиях плат, построенных на базе тех же графических процессоров, что используются и в потребительских картах). Поэтому, когда Barts уже был переведен на 40 нм, Cayman до последнего оставался 32-нанометровым согласно первоначальным планам. С учетом внешних обстоятельств команда разработчиков AMD вынужденно приступила к созданию 40 нм версии GPU, но если бы у AMD был тогда реальный выбор, Cayman без сомнения был бы выпущен на 32 нм оборудовании.  В результате, представший сегодня перед нами чип не является в полной мере тем, что в AMD планировали создать на 32 нм. Компания держит в секрете некоторые детали, которые отличают выпущенные 6970 и 6950 от планируемого ГП (ведь должны же оставаться определенные сюрпризы для 28 нм последователей 6900), но некоторые моменты очевидны. Первый из них это, конечно же, физический размер; стратегия AMD по выпуску компактных кристаллов отнюдь не мертва, но отсутствие 32 нм линий привело к непредвиденному отходу от намеченного вектора развития. При площади в 389 кв. мм Cayman является самым большим графическим процессором AMD после R600, и, безусловно, совершенно не соответствует разумной планке в 300 квадратных миллиметров. С другой стороны, в эффективности проектирования AMD не откажешь, ведь 2.64 миллиарда транзисторов (прирост в 500 миллионов относительно Cypress) — это на 29% больше, чем у предшественника при увеличении размера только на 16%. Но даже с такими неоднозначными показателями в дизайне чипа пришлось пойти на компромисс между функциональностью/числом блоков и себестоимостью производства. Инженерам AMD пришлось не просто выпустить массивный GPU, но еще и отказаться от некоторых задумок, чтобы избежать чрезмерного роста площади, энергопотребления и тепловыделения. Безусловно, основные потери составляют блоки SIMD; у 32 нм Cayman вычислительных кластеров, напрямую влияющих на быстродействие, было бы однозначно больше. Что касается функциональности, здесь представители AMD хранят молчание. Известно, что для 32 нм чипов была запланирована поддержка PCI-Express 3.0, но в итоге был применен контроллер шины версии 2.1 меньшего размера. Впрочем, это не так страшно, так как официальное одобрение стандарта PCIe 3.0 было отложено до ноября, так что реальных материнских плат с такими слотами ждать еще как минимум несколько месяцев. В конечном итоге, получившийся Cayman является в некотором роде компромиссным решением из-за ограничений 40 нм техпроцесса. Компании удалось внедрить обновленную архитектуру VLIW4, но производительностью и неизвестным набором возможностей пришлось пожертвовать, чтобы не выходить за допустимые рамки физических размеров кристалла. Можно посмотреть на этот факт и с иной, позитивной точки зрения — ведь следующее 28 нм поколение чипов должно стать особенно интересным и даже превзойти те спецификации, которые изначально были определены для 2010 года, но так и не были реализованы «в железе». [N4-VLIW4: в поисках баланса между TLP, ILP и остальными компонентами] Чтобы корректно обосновать, почему AMD было принято решение об использовании архитектуры VLIW4, необходимо вернуться к истокам формирования VLIW5. Для этого нам потребуется вспомнить эпоху DirectX 9; с нее и начнем. В те дни, когда программирование с использованием шейдеров только начинало развиваться, а пиксельные и вершинные шейдеры были разделены, в ATI разработали дизайн VLIW5 для обработки вершинных компонентов. Основываясь на статистических данных по различным игровым продуктам, было определено, что оптимальной конфигурацией является такой вершинный блок, который сможет одновременно рассчитывать четыре компоненты точки (например, w, x, y, z) и какую-нибудь скалярную составляющую (например, освещение). Теперь перенесемся в 2007 год к моменту выпуска ATI Radeon HD 2000 (R600) — первой унифицированной архитектурой ATI для персональных компьютеров. В ней вновь было решено использовать VLIW5, так как даже при очевидной направленности на DirectX 10 необходимо было сохранять преемственность, обеспечивая высокую производительность и в DX9 приложениях. Отметим также, что данные события происходили задолго до распространения концепции GPGPU вычислений.  Планомерное развитие шло своим чередом, в 2008 появилось новое поколение видеокарт, которые можно считать уже не столь далекими предками сегодняшнего Cayman. Впрочем, кардинально измениться за прошедшее с момента выхода Vista и DX10 время ситуация на рынке не успела. Действительно, у графического подразделения AMD было время на то, чтобы исправить критические недостатки R600 в RV670 и RV770, но GPGPU рынок так и не вырос серьезно к тому моменту, а DX10 не получили широкого распространения. Но уже тогда, задумываясь о будущем, инженеры AMD строили прогнозы на грядущие годы, определяя необходимые темпы внедрения тех или иных технологий. По их расчетам, математические вычисления средствами графических процессоров должны таки были стать востребованными, а DX9 игры — уйти в прошлое на фоне DX10/11 новинок. Пришло время пересмотра служившей верой и правдой VLIW5. Это и подводит нас к анонсу Cayman и сегодняшнему дню. Действительно, GPGPU находится на подъеме, а игры DX10 и DX11 получают все большее распространение вместе с Windows 7, тогда как пик популярности DX9 давно остался в прошлом. По информации из собственной базы данных AMD, средняя величина загрузки имеющихся шейдерных процессоров составляет 3.4 единицы, т.е. пятый потоковый процессор практически не используется в современных играх. Тогда как для вычислений вершинных шейдров DX9 VLIW5 подходила идеально, в сегодняшних реалиях она перестала быть оптимальным решением. Ставка была сделана на «сужение» функциональности SPU и переход к VLIW4. Как вы можете помнить из наших прошлых описаний базовой архитектуры современных видеочипов AMD, она сильно зависит от параллелизма на уровне инструкций (Instruction Level Parallelism, ILP). Это означает оптимальную работу GPU при наличии нити команд с отсутствующими зависимостями, что равносильно возможности их одновременного запуска на исполнение. Логично, что для VLIW5 лучшим сценарием работы могут стать пять подобных инструкций, отданных планировщиком одному SPU на такт, однако такой идеальный случай выпадает довольно редко. Чуть выше мы уже упоминали, что согласно официальным данным AMD, в среднем получается задействовать только 3.4 блока, что ниже желаемого КПД хотя бы в 80%. Реализовывать весь потенциал чипа из-за сложности получения ILP в коде непросто, поэтому разница между лучшей и худшей производительностью GPU может быть весьма велика.  Такой подход серьезно отличается от параллелизма на уровне нитей (Thread Level Parallelism, TLP), смысл которого заключается в одновременном исполнении не зависящих друг от друга потоков команд. Именно по этому пути пошла NVIDIA при создании своих высокопроизводительных скалярных процессоров GF100/GF110 Fermi. Всегда было ясно, что подход AMD VLIW5 не является наиболее эффективным и может применяться до поры до времени. До сих пор экстенсивное развитие работающих по этим принципам процессоров давало неплохие результаты, чего стоит хотя бы высокая игровая производительность серии 6800. Но, осознавая слабые стороны своей реализации ILP, в AMD хотели устранить их, одновременно подготовив базу для будущего развития. Причем, цель была не только в оптимизации SPU для соответствия условной игровой нагрузке на 3.4 потоковых процессора, но и в улучшении вычислительных способностей чипов. В результате, решено было серьезно модернизировать существующий каркас, взяв все лучшее от VLIW5, и изменив баланс сил в соответствии с современными требованиями. В такой ситуации совершенно естественным видится «сужение» VLIW5 SPU до VLIW4 SPU. Достигнуто это было путем отказа от сложного t-блока — последнего из пяти входящих в состав SPU потоковых процессоров, умеющего проводить не только стандартные INT/FP операции, но и расчеты трансцендентных функций. В случае с базовой INT/FP функциональностью это означает, что один SPU теперь способен в теории исполнять только 4 операции за такт вместо 5. Что же касается трансцендентной математики, то для ее расчетов теперь должны объединиться 3 SP. Здесь падение скорости «на бумаге» существенно более выраженно, так как вместо 1 трансцендентной операции и 4 INT/FP, как это было раньше, VLIW4 способна обеспечить только 1 трансцендентный и 1 обычный INT/FP расчет за такт.  У таких кардинальных изменений есть четкое обоснование. Дело в том, что отказ от пятого модуля в SPU освобождает физическое пространство на кристалле, а, значит, даже если не принимать во внимание частоту использования различных функций, при одной и той же площади может разместиться больше SPU VLIW4, чем VLIW5. У Cypress 20 SIMD кластеров, тогда как у Cayman — 24. При этом в среднем шейдерный блок Cayman обладает на 10% большей эффективностью на квадратный миллиметр, чем Cypress, а ведь размер самих ALU VLIW4 несколько увеличился из-за «перераспределения обязанностей». Далее, сложная взаимосвязанная архитектура чипа ведет и к зависимости числа SIMD и целого набора факторов: количества текстурных модулей, количества нитей, одновременно обслуживаемых GPU, наконец, количество FP64 операций за такт во всем процессоре. Последний пункт вкупе с довольно производительными вычислениями 64-битной точности FMA/MUL на скорости в 1/4 от FP32 особенно важен в свете стремления AMD улучшить вычислительные возможности Radeon (до 384 единиц в случае с полноценным Cayman). Иными словами, хотя по удельным показателям FP64 быстрее не стали, благодаря новой структуре GPU достигается общее ускорение.
Стоит упомянуть и дополнительные бонусы, которые получили SPU в связи с реструктуризацией. Так, хотя число SP уменьшилось, регистровый файл остался нетронутым, так что теперь для прямой работы с данными у процессоров есть больше пространства. Распределение нагрузки для диспетчера также упростилось, так как теперь индивидуальных ядер не только меньше, но они все однотипны, а, значит, нет необходимости учитывать различия между w/x/y/z и t-модулями. С точки зрения чисто игрового применения, достоинства обновленной VLIW4 проявляют себя схожим образом. Как мы уже знаем, подавляющее большинство игр не было способно реализовать весь потенциал SPU VLIW5, так что отказ от пятого SP не должен сильно навредить. Напротив, большее количество SIMD обеспечит увеличение скорости рендеринга, так как эта задача очень хорошо распараллеливается (по крайней мере, на уровне нитей). Кроме того, дополнительные SIMD означают и расширение возможностей Cayman в текстурировании относительно Cypress. Получившееся соотношение вычислительных возможностей и текстурной производительности оказалось смещено в сторону классических функций GPU, так что теперь игры, в которых бутылочным горлышком является именно быстродействие текстурирования/фильтрации, должны чувствовать себя комфортнее. Однако следует понимать, что любые архитектурные изменения не могут быть исключительно положительными. Так, существует определенный класс игр, для которых отказ от VLIW5 в Cayman нежелателен. Конечно, речь идет о тех приложениях, в которых часто используются вершинные шейдеры, VLIW4 справляется однозначно хуже предшественника. Но подобные требования типичны не для современных хитов, а для игр прошлых поколений, да и уровня производительности Cayman в любом случае будет более чем достаточно для таких приложений. Напомним, что при создании VLIW4 стояла цель актуализации имеющейся архитектуры и ее подготовки для будущих задач, так что не будем корить AMD за потенциально худшую работу Radeon HD 6900 в устаревающих играх. Еще одним минусом является необходимость траты двух (или более) тактов при сочетании вычисления трансцендентной функции с несколькими векторными операциями. Но, по словам представителей AMD, такая ситуация возникает довольно редко, и получаемые в ней VLIW5 лучшие результаты несоизмеримы с общими дивидендами, которые дает VLIW4. Интересно и то, что AMD называет VLIW4 рискованным/экспериментальным дизайном; на Cayman компания планировала обкатать свое новое видение архитектуры будущих Radeon HD, оставив при этом VLIW5 во всех прочих видеокартах 6000 семейства. Рискнем предположить, что на самом деле все эксперименты уже давно подошли к концу в лабораториях AMD, и именно VLIW4 определен как дизайн будущего. Скорее всего, компания находится уже в середине процесса создания 28 нм последователя Cayman, и безо всяких сомнений он будет основан на концепции VLIW4. Наконец, изменение идеологии архитектуры VLIW означает и необходимость применения новых методик в написании драйверов командой программистов AMD. Конечно, с пользовательской точки зрения VLIW4 не слишком отличается от VLIW5, но на более низком уровне эти структуры серьезно разнятся. Это одновременно и хорошо, и плохо для производительности. Негативный момент состоит в том, что имеющиеся наработки, созданные с прицелом на максимально эффективное использование VLIW5, больше не могут быть использованы. Так что, на старте возможности Radeon HD 6900 не будут раскрыты полностью. С другой стороны, быстродействие плат, без всяких сомнений, будет улучшаться с новыми релизами драйверов, и в этом заключается хорошая новость. Не должны остаться в стороне и разработчики. Изменения в VLIW следует учитывать в коде игровых движков для лучшего взаимодействия с новыми видеокартами. Шейдерный компилятор AMD обучен оптимизировать существующий код в автоматическом режиме, но, если изначально игра была заточена для VLIW5, без рефакторинга не обойтись. Заметим, что не так много разработчиков пишут разный код для обеих распространенных архитектур ввиду множества причин, включая экономическую целесообразность и т.п., но именно подобный подход позволяет извлечь максимум из возможностей ILP/TLP GPU и добиться лучшей шейдерной производительности. VLIW5:
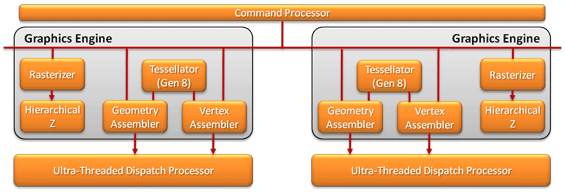
Первая из причин, по которой VLIW4 является серьезной угрозой для Fermi, является асинхронное распределение задач, понятие, которое хорошо говорит само за себя. Здесь позволим себе напомнить о Fermi вновь, потому как именно с этой архитектурой NVIDIA сделала возможным одновременный запуск множественных параллельных ядер. В свою очередь, AMD воспользовалась удачной идеей конкурента, однако пошла в реализации еще дальше. Ограничение дизайна NVIDIA заключается в том, что хотя Fermi и способен запускать несколько ядер одновременно, все они должны быть приняты на обработку от одной нити команд CPU. Независимые потоки/приложения не могут просто так раздельно передавать ядра и запускать их параллельно, GPU для отработки подобной ситуации требуется переключение контекста. С внедрением асинхронного распределения задач AMD решает эту проблему; Cayman способен запускать независимые нити/приложения параллельно. По крайней мере, теоретически это должно дать AMD существенное преимущество в подобного рода ситуациях, так как смена контекста не является «дешевой» операцией с точки зрения потребления ресурсов. Преимущество это может быть столь значительно, что способно нивелировать имеющееся опережение GeForce.  На фундаментальном уровне асинхронное распределение достигается путем «утаивания» GPU определенной информации о своем реальном состоянии от приложения и ядер, что, по сути, представляет собой некий вариант виртуализации ресурсов графического процессора. Каждому ядру представляется, что оно запущено на выделенном GPU, имеет собственную очередь команд и адресное пространство. На самом же деле, вся работа по распределению разноплановой нагрузки ложится на процессор и драйверы. Хотя такая система сложнее в реализации, она дает ощутимый выигрыш в быстродействии по сравнению с применяемым NVIDIA принципом переключения контекстов. Обратная сторона данной технологии заключается в необходимости программной поддержки со стороны API. К сожалению, в текущей реализации единого стандарта DirectCompute 11 она не поддерживается, так что в ближайшее время асинхронное распределение будет доступно в качестве расширения OpenCL. Прочие улучшения, проделанные AMD, направлены на улучшение производительности памяти и кэша. Хотя базовая архитектура остается без изменений, некоторые мелочи могут положительным образом влиять на затрачиваемое на вычисления время. Так, локальные хранилища данных (Local Data Store, LDS), подключенные к SIMD, отныне соединены с VRAM напрямую, и выборки из памяти теперь могут попадать в них, минуя иерархию кэш-памяти и глобальное хранилище данных (Global Data Store, GDS). Кроме того, в Cayman был добавлен второй движок DMA, улучшающий показатели чтения и записи, а также дающий возможность параллельного запуска двух этих процессов в каждом направлении. Наконец, было несколько ускорено чтение из шейдерных процессоров; в отличие от Cypress, Cayman может объединять несколько запросов и сокращать число операций. Отметим, что, так как данный материал посвящен главным образом линейке Radeon HD 6900, мы не стали подробно останавливаться на всех мелочах новой архитектуры. Они будут интересны главным образом профессионалам, покупателям Firestream, и не окажут значимого влияния на решение о выборе игровой видеокарты. [N6-Улучшение работы с примитивами: двойной графический движок и новые ROP] Похоже, что AMD приняла комментарии NVIDIA по поводу геометрической производительности современных GPU близко к сердцу. Вместе с обозначением своей позиции по данному вопросу с релизом серии 6800, в компании продолжали работать над увеличением быстродействия блоков геометрии для будущих решений. В результате, фиксированный графический движок (Graphics Engine) был значительно улучшен в Cayman. До Cypress, в чипах AMD присутствовал единственный графический движок, включающий в себя каждый из следующих необходимых модулей в одном экземпляре: иерархический z-буфер и блок растеризации, трансляторы геометрии и вершин, а так же тесселятор. В RV870 AMD удвоила z-буфер и модуль растеризации, что позволило за такт обрабатывать до 32 пикселей против 16 ранее. Тем не менее, хотя инженеры частично усовершенствовали графический движок, не все его части были улучшены. Так, по примитивам никаких изменений внесено не было, и комплекс мог выдавать только одну единицу за такт, что соответствовало стандартам на то время.
В 2010 году с запуском Fermi NVIDIA значительно подняла планку по данному параметру. Функции растеризации в чипах GeForce переместились в GPC, и в GF100/GF110 NV довела количество выдаваемых за такт примитивов до числа этих самых графических кластеров. В рамках одного поколения модернизация была просто революционной, особенно на фоне вялотекущих изменений за многие годы до этого. В Cayman AMD предприняла попытку сократить отставание от NVIDIA в вопросах геометрии, улучшив собственные показатели работы с примитивами. Правда, о столь впечатляющем приросте говорить не приходится. При создании Cayman, нетронутые ранее в Cypress оставшиеся части Graphics Engine были удвоены и разнесены — во флагманском видеопроцессоре AMD отныне имеется два раздельных графических движка, каждый из которых наделен базовой функциональностью и способен выдавать 1 примитив за такт. В сумме это и дает уровень, вдвое превосходящий возможности Cypress. Правда, во столько же раз топовый чип семейства Southern Islands уступает и high-end решениям NVIDIA.
Как это могут подтвердить коллеги из NVIDIA, разделение растеризации и тесселяции оказалось не такой простой задачей. Трудность у команды AMD возникла на этапе создания попросту отсутствующего ранее механизма балансировки нагрузки между модулями для максимально полной загрузки их работой. По словам представителей графического подразделения AMD, решить этот вопрос удалось очень элегантно, и дальнейшее наращивание мощности части чипа, ответственной за геометрию, будет происходить прозрачно и без дополнительных доработок. С этой позиции Radeon HD находится в выигрыше, так как NV необходимо следить за отношениями GPC/SM/SP при модернизации своих чипов. В конечном счете, все эти действия сами по себе не слишком важны на данный момент; фактически, они являются только подготовительными этапами для увеличения производительности столь важной для DX11 тесселяции. В аппаратном блоке тесселяции 7ого поколения скорость при малых факторах уже была повышена, так как в этом случае ограничительным фактором были сами возможности тесселяции Cypress. Но при высоких факторах проблемой был именно графический движок, который «захлебывался» с поступлением на вход большего числа примитивов, чем он способен обработать. Теперь, когда в Cayman имеется два выделенных Graphics Engine, предел по растеризации двух примитивов за такт перестает быть ограничителем. Сам факт наличия двух тесселяторов, аналогичных седьмому поколению Barts, является весомым преимуществом Cayman. Однако такую сложную структуру необходимо обеспечивать и соответствующей «обвязкой», так как быстроты геометрического движка все равно может не хватать, а, значит, промежуточные данные должны где-то храниться, ожидая свой черед на обработку. К сожалению, величины кэшей в Cayman остались неизменными, а это означает, что на старое хранилище данных может приходиться втрое больше данных. Было принято решение размещать их в набортной видеопамяти. Не самое оптимальное решение с точки зрения быстродействия, но оно в любом случае лучше, чем ожидание всего конвейера рендеринга окончания процессов растеризации.
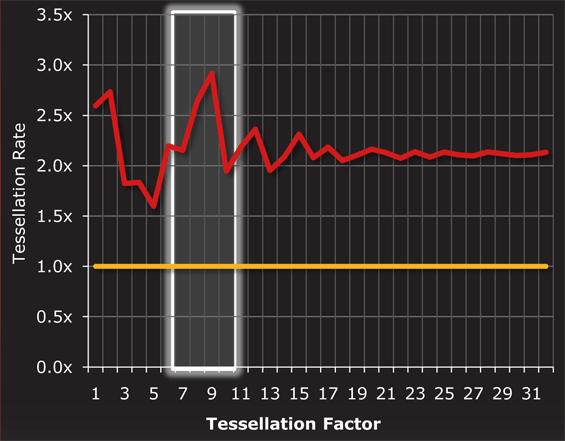
В общем и целом, на одной тактовой частоте тесселяция в Cayman происходит от полутора до трех раз эффективнее, чем в Cypress. В ситуациях, где AMD уже улучшила быстродействие тесселяции в Barts, может достигаться трехкратное преимущество (низкие факторы), тогда как при коэффициенте 5 разница составляет минимальные полтора раза. В среднем производительность возросла вдвое, что хорошо коррелируется с удвоением графических движков. Кроме того, тесселяция является одной из причин, по которым AMD серьезно переработала модули ROP. Результат работы тесселятора — заметно более детализированная геометрия моделей, выражающаяся в большом количестве мелких треугольников, которые очень сложно обрабатывать ROP при выполнении MSAA. Общее количество ROP осталось прежним — 32 штуки, но определенные операции они теперь исполняют существенно быстрее. В обоих случаях расчетов подписанных и неподписанных нормированных INT16, разработчики могут использовать преимущества двукратного ускорения. С FP32 Cayman работает от 2 до 4 раз быстрее в зависимости от сценария. Наконец, похожим на чтение из регистров шейдерных процессоров образом, для ROP была добавлена возможность объединения запросов на запись и сокращение их общего числа. [N7-Определяем TDP по-новому: PowerTune] Одним из бенчмарков, используемых нами в тестированиях на постоянной основе, является FurMark от oZone3D. Эта утилита предназначена для того, чтобы вывести видеокарты в режим максимального энергопотребления. «Волосатый бублик», как эту программу часто называют энтузиасты, способен генерировать такую нагрузку, которая практически недостижима ни в реальных играх, ни в GPGPU приложениях. Нужно это для того, чтобы определить, сколько энергии требует плата, до какой температуры разогревается GPU, и насколько громко работает система охлаждения в самом худшем варианте развития событий. Тот факт, что это ПО столь грубо обращается с картами, демонстрируя нетипичные для реальных игр результаты, стал причиной того что оба ведущих производителя окрестили FurMark «энергетическим вирусом» и начали встраивать разнообразные защиты от подобных утилит.  Откровенно говоря, вся эта история с FurMark является не причиной, а следствием большой проблемы; здесь мы говорим о TDP. Конечно, прямое сравнение здесь не совсем корректно, но центральные процессоры с максимальным TDP порядка 140 Вт являются просто эталонами экономичности по сравнению с монструозными графическими картами. Спецификации стандарта ATX определяют максимальное энергопотребление PCI-Express устройств в 300 Вт, в наших тестах эта граница зачастую преодолевается при запуске FurMark. Еще сложнее обстоит дело с мобильными ПК или компьютерами класса «все-в-одном», где ограничения свободного пространства и/или емкости батареи вместе с необходимостью использования компактных систем охлаждения для рассеивания тепла и вовсе ставят GPU в жесткие рамки. По этим причинам все платы должны соответствовать определенному тепловому пакету TDP. Скажем, чтобы уложиться в рамки 300 Вт, AMD пришлось снизить для Radeon HD 5970 частоты, хотя были использованы полноценные чипы 5870. По этой же причине в ноутбуках нередко можно встретить графические карты, обрезанные по числу функциональных блоков и с минимальными частотами. Хотя мы не раз видели, что платы AMD и NVIDIA превышали заявленные значения TDP в FurMark, разница между номинальным и фактическим значением никогда не была криминальной. Ведь хотя производители давно отошли от практики приравнивания TDP к максимальному энергопотреблению устройства, постоянное превышение этого усредненного значения на значительную величину ведет к перегревам и возможному механическому повреждению оборудования. Именно из-за подобных FurMark программ разработчикам приходится создавать некоторый запас прочности для GPU, тем самым несколько снижая их производительности. В Call of Duty, Crysis и The Sims 3 проблем при более высоких частотах практически гарантированно не возникло бы на большинстве видеокарт, но необходимость перестраховки определяется по худшему из сценариев. Все это подводит нас к концепции, которая уже реализована в современных центральных процессорах в виде технологий Turbo Boost от Intel и Turbo Core от AMD. Очевидно, что в зависимости от типа нагрузки в большей или меньшей степени загружаются различные блоки GPU, определяя при этом и TDP. В частности, при некачественной оптимизации GPU может практически простаивать, а плата при этом будет потреблять совсем немного энергии. Чем не повод, чтобы поднять частоты и напряжения, улучшив производительность самым простым путем? Напротив, в FurMark и прочих «тяжелых» программах частоты можно снижать относительно базовой планки, которую в случае с динамическим регулированием можно установить выше, чем это обычно делается с учетом необходимости оставить запас по TDP. 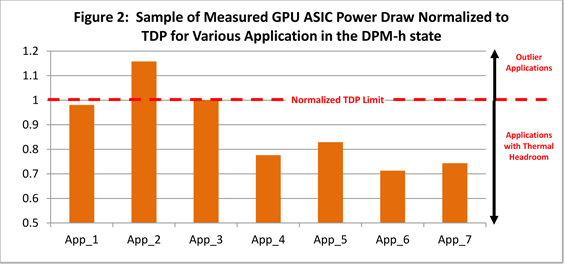 Получается, что д |
|||||||||
Источник: www.anandtech.com/