Каталог
Об архитектуре GF100Итак, NVIDIA GeForce GTX 480 и 470 основаны на GPU под кодовым названием GF100, игровой версии архитектуры Fermi, которая была изначально представлена в сентябре прошлого года. GF100 служит базой для серии GeForce; чип, который NV так и называет, Fermi, предназначен для плат Tesla. Фактически они идентичны и различаются в деталях. На высоком уровне, GF100 выглядит как укрупненный GT200, но это впечатление ошибочно. Возьмем хотя бы начальную стадию работы чипа. До GF100 NVIDIA использовала большой унифицированный модуль, функции которого состояли в планировании задач для потоковых процессоров, установке граней треугольников, растеризации и отбрасывании невидимых поверхностей. Так это выглядит на общей диаграмме GT200:
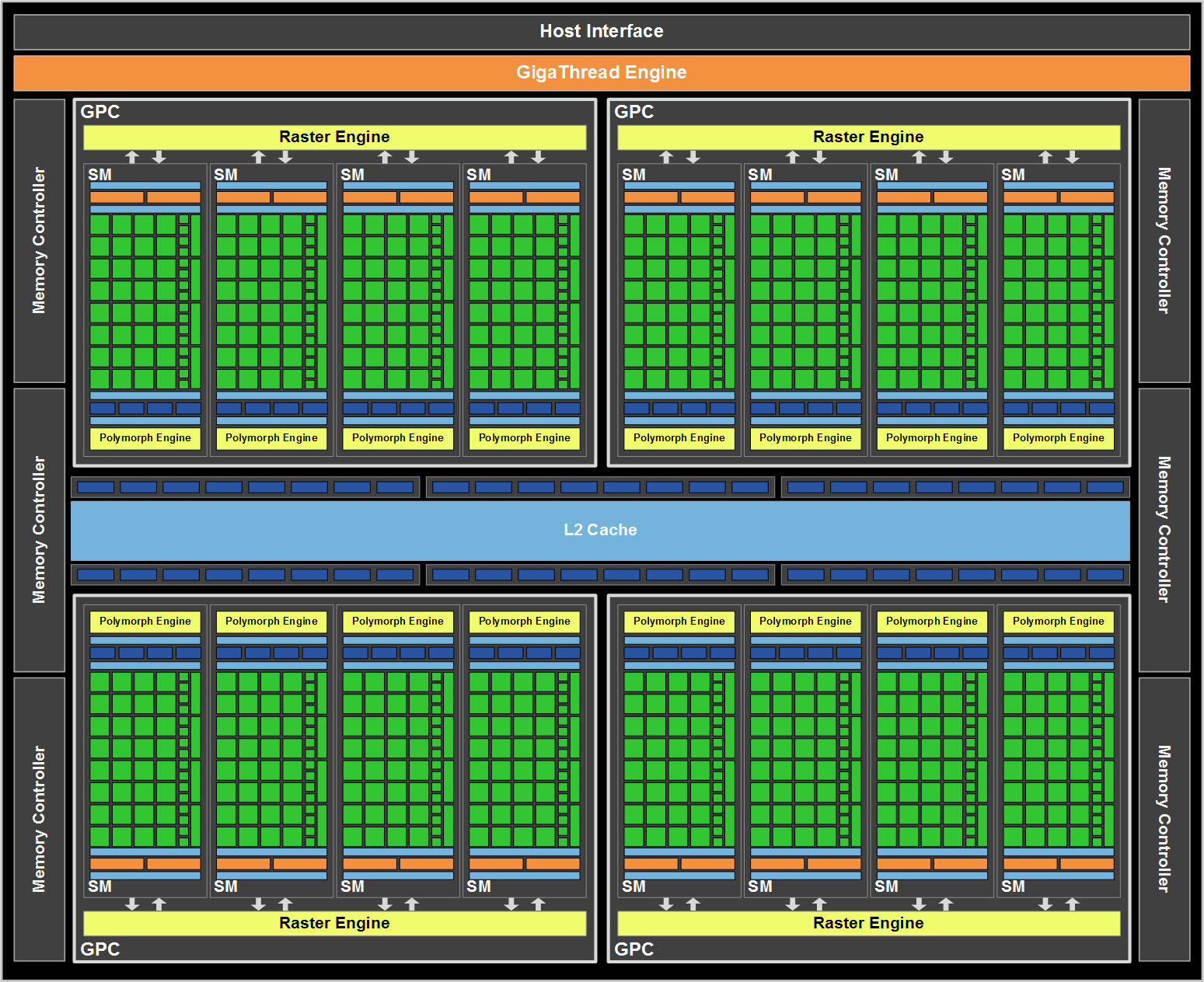
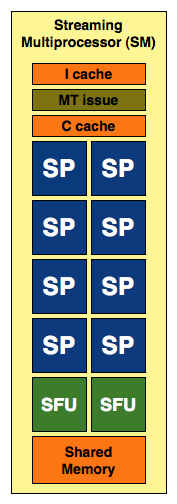
Четверка серых блоков, расположенная сверху, обслуживает все вычислительные кластеры GPU. В GF100 же этот ранее основополагающий модуль утратил свою значимость: многие из его функций были отрезаны и перенесены на более низкие уровни конвейера рендеринга. За исключением планировщика задач чипа, все прочие функциональные блоки инженеры уменьшили в размерах, увеличив при этом их количество, и перенесли ближе к исполнительным модулям. Это было сделано для улучшения масштабируемости архитектуры. К тому же с увеличением размеров графических процессоров все сложнее становится заставить разделяемые многофункциональные части GPU работать эффективно. В прошлом NVIDIA поступала следующим образом при группировке своих GPU с унифицированной шейдерной архитектурой: объединялось несколько ядер, они наделялись кэшем, некоторым массивом общей памяти, а также парой блоков для специализированных задач (Special Function Unit, SFU). Все это вместе называлось потоковым мультипроцессором (Streaming Multiprocessor, SM). В GT200 тройка таких SM вместе с некоторым количеством текстурных модулей и текстурной кэш-памятью первого уровня (и определенным внутренним распределителем задач) образовывала текстурно-процессорный кластер (Texture/Processor Cluster, TPC). Флагман предыдущей генерации, GeForce GTX 280, имел в своем составе 10 таких TPC, которые и формировали вычислительную мощь чипа.
С переходом к GF100, NV отказалась от прошлого шаблона построения GPU и структуры TPC. Отныне чип состоит из кластеров обработки графики (Graphics Processing Cluster, GPC) и имеет намного больше SM. SM набраны 32 ядрами, и в одном GPC находится четыре SM. У каждого GPC имеется свой выделенный растровый движок, вместо использовавшегося ранее общего на весь чип блока. Из схемы понятно, что у GF100 всего четыре таких крупных GPC, но, как вы уже знаете, ни у одного из продаваемых сегодня GeForce на базе GF100 не активированы все имеющиеся SM.   Теперь все вычисления на уровне ядер соответствуют спецификациям IEEE. Речь идет о стандарте IEEE-754 2008 для вычислений с плавающей запятой (то же самое реализовано и в RV870/HD 5870) и полной поддержке 32-битной точности для целых чисел. Например, ранее умножение 32-битных целых приходилось эмулировать, аппаратно производилось лишь 24-битное умножение. Теперь все подобные проблемы, приводящие в определенных случаях к заметной потери производительности и, потенциально, даже к недостоверным результатам, остались в прошлом. Добавили и новые инструкции, такие как одновременное сложение и умножение (Fused Multiply Add, FMA). Проведенные оптимизации преследовали цель создания чипа, соответствующего всем индустриальным стандартам точности; требовалось уйти от различных вспомогательных способов при вычислениях, чтобы при любых операциях результат соответствовал ожиданиям. Что касается нецелочисленной математики удвоенной точности (FP64), производительность здесь скачкообразно возросла. В пике скорость исполнения инструкций по работе с 64-битными FP отныне лишь вполовину меньше 32-битных FP, хотя ранее наблюдалось восьмикратное падение (показатель AMD для FP64 — 1/5 от FP32).
Как и ранее, SM включают в себя не одни лишь ядра. Для трансцендентной математики и интерполяции все так же используются отдельные SFU. В GT200 SM был наделен двумя SFU, в GF100 их теперь четыре. Интересно, что баланс между общей вычислительной мощностью и возможностями SFU изменился — четырехкратный прирост ядер в SM дополняется лишь двукратным ростом количества блоков специального назначения.
В распоряжении каждого SM GT200 было 16 Кб разделяемой памяти. Тем не менее, как кэш, в прямом смысле этого слова, данный массив функционировать не мог. Это была скорее программно управляемая память. В GF100 объем этого буфера вырос до 64 Кб, и теперь это можно назвать реальным L1 кэшем. Для того чтобы сохранить совместимость с приложениями CUDA, написанными для G80/GT200, эта 64 Кб память может быть сконфигурирована как 16/48 Кб или 48/16 Кб разделяемой памяти/L1 кэш. Помимо того, нетронутым остался и 12 Кб L1 кэш текстур, который был по большому счету бесполезен для программ CUDA. Наконец, все четыре GPC имеют доступ к общему 768 Кб L2. 
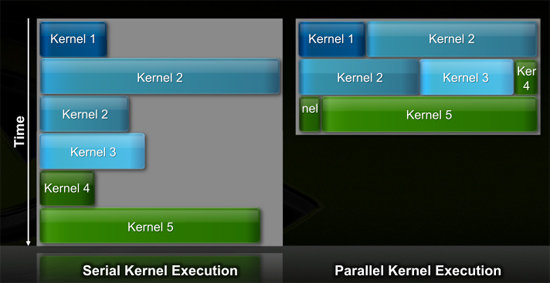
Наконец, последние по списку, но не по значению, — ROP. Они были также реорганизованы, теперь 48 модулей разбиты по 8 единиц в 6 групп, к каждой из которых подведен 64-битный канал памяти. Отныне ROP имеют доступ к общему L2 кэшу GF100, тогда как в GT200 они обладали собственным кэшем второго уровня. Каждый ROP обсчитывает 1x стандартный 32-битный пиксель за такт, 1x FP16 пиксель за 2 такта, или же 1x точку FP32 точности за 4 такта. То есть возможна обработка 48 обычных пикселей за такт. Частота работы ROP равняется таковой у общего L2. [N6-Нити и планирование задач] Тогда как NVIDIA G80 мог выполнять общие вычисления вследствие своей скалярной архитектуры, и это рассматривалась как дополнительный вариант применения GPU, GF100/Fermi проектировался с оглядкой на иные приоритеты. Реализации прошлых архитектур предполагали, что все SM чипа должны работать над одной и той же задачей (функцией, программой, циклом) в определенный момент времени. Если задача была недостаточно хорошо распараллеливаема, чтобы загрузить работой все имеющиеся в наличии ядра, то они банально простаивали, а эффективность чипа в результате падала. Так что говорить о высоком КПД унифицированной архитектуры возможно было лишь при условии работы с соответствующим ПО. В новом поколении своей архитектуры, NVIDIA наделила планировщик задач новой функциональностью: теперь стало возможным параллельное исполнение нитей из разных задач. Это один из ключевых факторов, благодаря которым NV смогла увеличить количество SP в GF100, как минимум, без снижения эффективности их работы.
Было на порядок уменьшено время переключения контекста между режимами GPU и CUDA. Теперь эта задержка настолько незначительна, что возможно многократное переключение даже в пределах одного кадра. Это должно позволить более широко использовать PhysX. С точки зрения работы с нитями, GT200 был настоящим монстром, способным на лету поддерживать до 30 000 потоков. Оказывается, данные показатели были даже избыточны. Бутылочным горлышком служила ПСП, а не возможность одновременного поддержания в работе такого количества нитей, так что в GF100 это число даже снизили до 24 тысяч.
NVIDIA совмещает 32 нити в одну группу, называемую "варпом" (warp). В GT200 и G80 половина подготовленного варпа передается в SM на каждый такт. То есть для передачи в SM всего набора из 32 нитей требуется два такта. В прошлых архитектурах логика диспетчера SM была тесно связана с исполняющими модулями. Если какие-либо инструкции передавались на исполнение в SFU, весь SM ожидал окончания операции и не мог перейти к обработке следующих позиций в нитях. При этом если выполнение определенных команд предполагало использование одних только SFU, подавляющее большинство возможностей SM в GT200/G80 просто не использовались. Ясно, что это негативно влияло на общую эффективность. В Fermi этот недостаток устранили. Теперь в чипе присутствует два независимых диспетчера на каждый SM. Эти блоки уже не связаны так тесно с внутренней структурой SM. Каждый из этих двух модулей может выбирать и отсылать на исполнение половину варпа за такт. При этом нити могут принадлежать различным варпам для как можно большего параллелизма и нахождения независимых операций. Логика распределения задач представлена двумя независимыми модулями одного уровня, они равноправно распоряжаются ресурсами внутри SM. Недостаток решения NVIDIA состоит в том, что каждая нить в варпе должна исполнять одинаковую инструкцию в одно время. Если так происходит, то достигается полное использование ресурсов. Если нет, то некоторые модули простаивают. Один SM может выполнять:
Если на исполнение запускается инструкция FP64, то весь SM может производить 16 операций за такт. Одновременное исполнение операций FP64 и SFU невозможно. Хорошие новости состоят в том, что SFU теперь не привязан полностью ко всему SM. Один диспетчер может с легкостью послать 16 нитей соответствующему массиву ядер, тогда как второй — 16 нитей на SFU. По прошествии двух тактов диспетчеры могут вновь отправлять половины варпов. Сравните это с существовавшей ранее необходимостью ожидания всем SM полных 8 тактов после отправки нитей на SFU. Чувствуется, что на каждом уровне Fermi была проделана качественная работа по максимальному "развязыванию" и дроблению блоков. Остается проверить одно — как эта гибкость поможет GF100 в реальных приложениях. [N7-Некоторые особенности: ECC и отсутствие NVIDIA Surround] Еще один из моментов, о которых рассказывала NVIDIA на предварительных мероприятиях, посвященных выпуску Fermi, — поддержка режима коррекции ошибок ECC. Fermi предлагает ECC для своего регистрового файла, кэшей первого и второго уровней, а также набортной видеопамяти. Последнее особенно интересно в свете того, что при обычных обстоятельствах внедрение ECC сопряжено с необходимостью организации более широкой шины и установки дополнительных чипов памяти. Хотя в игровой серии GTX 400 данная технология и отключена, мы расскажем, как работает ECC на Fermi, так как подход NVIDIA интересен. Так, для того чтобы организовать ECC на обычных модулях PC DIMM, необходимо 9 чипов на один канал (9 бит на байт), подключенных к 72-битной шине, вместо стандартных 8 чипов и 64-битного канала. Тем не менее, у NVIDIA не было ни желания, ни возможности добавить еще больше разрядности шине памяти и установить больше чипов GDDR5, не говоря уже о том, что 8 не делится без остатка на 10/12 каналов памяти. Так как же инженеры смогли воплотить ECC на имеющейся конфигурации? На самом деле, принцип здесь довольно прост. Когда пользователь хочет активировать ECC, карта резервирует часть набортной памяти под контрольные суммы ECC. Таким образом, VRAM просто уменьшается на 1/8 (для имитации работы девятого бита), и данные ECC располагаются в этой зарезервированной области. Поэтому прочие дополнительные затраты не требуются. Согласитесь, изящный путь решения поставленной задачи с минимальными потерями! С технической стороны, несмотря на нестандартную реализацию, NVIDIA использует обычные алгоритмы одинарной и двойной коррекции ошибок Single Error Correction / Double Error Detection (SECDED), поэтому вопрос о надежности технологии не стоит. При этом потеря производительности минимальна, даже ниже ожидаемых 12.5%. Каким образом удалось при фактическом сокращении пропускной способности добиться таких результатов, NV не говорит, ссылаясь на специфические методы собственной разработки. Переходя к более интересным для простого пользователя технологиям, упомянем о 3D Vision Surround, конкуренте Eyefinity, который демонстрировался NVIDIA на CES. На тот момент утверждалось, что эта дополнительная возможность будет доступна одновременно с запуском серии GTX 400, но, как и многое другое, связанное с Fermi, 3D Vision Surround запаздывает.   В качестве первого теста на производительность тесселяции был выбран Unigine Heaven 2.0, выпущенный всего пару недель назад. Во второй версии бенчмарка была добавлена возможность выбора уровней качества тесселяции (UH 1.0 заслужил славу чрезмерно нагружающего видеокарты), что позволит нам более полно оценить картину производительности при более и менее активном использовании тесселяции. Если способности GTX 480 в действительности настолько превосходят Radeon HD 5870, как утверждает NV, GF100 должен лучше справляться со сложными режимами UH 2.0. Так как Heaven, по сути, является синтетическим тестом (на данный момент полноценных DX11 игр не существует), мы будем говорить об относительной производительности тестируемых плат, а не о полученных абсолютных показателях и количестве кадров в секунду.
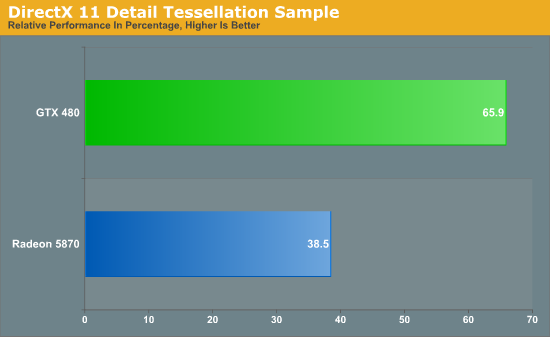
Heaven предоставляет выбор между четырьмя уровнями тесселяции: выключена, низкая, средняя, максимальная. Чтобы показать разницу в качестве, мы провели тесты с низкой и максимальной детализацией. На диаграммах — процентные показатели скорости карт, работающих с максимальной тесселяцией, относительно более низкой планки. 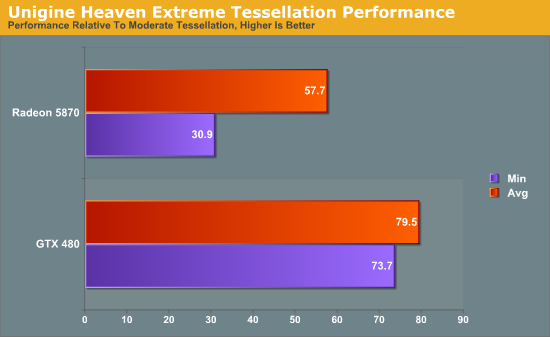 Минимальный фреймрейт еще более показателен. Тогда как новинка NVIDIA теряет 26%, Radeon HD 5870 показывает на 69% худшие результаты. Отчетливо видно, что со сложной тесселяцией GTX 480 справляется существенно лучше 5870. Вторым бенчмарком тесселяции выступила одна из демонстрационных программ Microsoft набора DX11: Detail Tessellation. Это сцена, в которой используется тесселяция и карты смещения, чтобы превратить плоскую текстуру скалы в реалистичную, сложную геометрически, модель. Здесь замерялось и сравнивалось между собой среднее количество кадров в секунду при двух уровнях качества (т.н. коэффициенты 7 и 11).
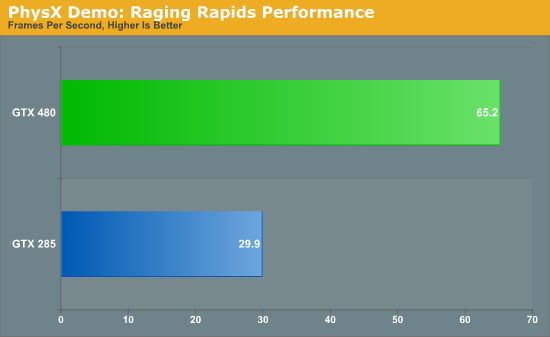
Однако сама по себе более мощная реализация аппаратной тесселяции ничего не означает. Применение данной технологии как таковой целиком и полностью зависит от разработчиков игр, в их же власти дать пользователям вручную выбирать и уровни качества тесселяции. На сегодня все игры, в той или иной мере использующие DX11, используют тесселяцию довольно ограниченно, поэтому дополнительные способности GTX 400 просто не используются. Конечно, это не означает, что так будет продолжаться всегда, но полагаться на только ожидаемые изменения в будущем — всегда рискованно. Превосходные возможности тесселятора NVIDIA требуют от разработчиков внедрения нескольких уровней качества тесселяции. Ведь необходимо обеспечить высокую производительность не только на GF100, но и на менее скоростных решениях AMD ценой некоторого упрощения геометрии. Как было отмечено выше, данные нововведения не слишком сложны и не меняют процесс разработки кардинально. Тем не менее, пока невозможно однозначно утверждать, будет ли производительность при тесселяции настоящим преимуществом GTX 400 в конкурентной борьбе с Radeon HD 5800, или же станет формальностью вроде DirectX 10.1 для HD 3800, удачной для рекламы, но малополезной в реальных приложениях. На сегодня мы не беремся рекомендовать GTX 480/470 к покупке исключительно из-за лучшей производительности новинок NVIDIA при тесселяции. Следующей технологией, требующей отдельного рассмотрения, является PhysX. В 2008 году NVIDIA купила разработчика AGEIA вместе со всеми программными и аппаратными технологиями, воплотив физический движок PhysX в качестве CUDA приложения для запуска на своих GPU. Тем самым, отпала необходимость в покупке специализированной платы. С того момента компания различными способами убеждала пользователей и разработчиков в преимуществах данной технологии, однако успех этого продвижения вряд ли можно было назвать однозначным. Пожалуй, "звездный час" для PhysX настал лишь в прошлом году с выходом игры Batman: Arkham Asylum, превосходно оцененной прессой и игроками. С заметно усовершенствованными вычислительными способностями Fermi, NVIDIA получила возможность говорить о лучшей производительности PhysX на новых картах, а, значит, и о потенциально более полном и частом использовании технологии для имитации сложных и реалистичных физических эффектов. К тому же, благодаря быстрому переключению контекста и поддержке конкурентных программ, накладные расходы PhysX на Fermi должны оказаться меньше, чем на GT200/G80. Чтобы проверить эти теоретические выкладки на практике, мы замерили производительность Batman: Arkham Asylum на картах разных поколений. Если PhysX на Fermi в действительности работает быстрее, чем на GT200, значит, количество кадров в секунду с включенным ускорением физики по сравнению с выключенным должно быть больше, чем на GTX 285. Тест был проведен в разрешении 2560x1600 при полностью отключенном PhysX, и установленном на высоком уровне качестве. 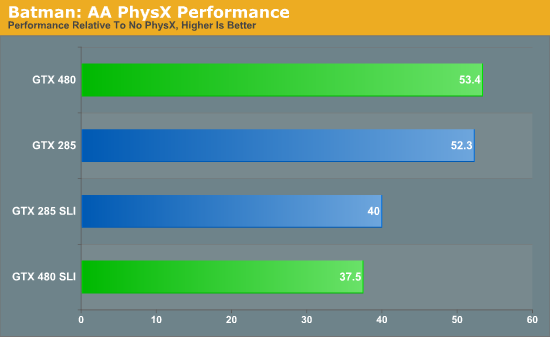 Без сомнений, текущая реализация PhysX на GTX 480 требует таких же затрат, как и на GTX 285. Если и стоит ожидать каких-то серьезных улучшений, то либо от совершенно новой версии PhysX 3, либо от одной из обновленных веток PhysX 2.x. На имеющихся сегодня играх плюсов GF100 не замечено. Второй тест призван дать более общее представление об уровне производительности PhysX. Мы использовали техническую демонстрацию NVIDIA Raging Rapids, которая изображает поток воды, а физика используется для реалистичного создания волн, водопадов и прочих явлений природы. На графике представлено количество FPS.
Продолжая исследование возможностей неграфических вычислений GF100, перейдем к более общим GPGPU задачам. Известно, что современные видеокарты с унифицированными шейдерными процессорами, обладая намного более простым устройством самих ядер по сравнению с CPU, могут значительно превосходить ЦП в хорошо распараллеливаемых задачах, где большое количество одновременно исполняемых потоков играет решающую роль. Серия GTX 400, будучи основанной на архитектуре Fermi, должна показывать прекрасную производительность в программах такого типа. Но не стоит переоценивать важность данных расчетов. Хотя в специализированных задачах GPU с 480 потоковыми процессорами может показать себя настоящим монстром, существует не так много реальных домашних неигровых применений GF100. Безусловно, доступны кодировщики видео на CUDA, ПО для обработки фотографий и т.д., но, хотя прошло уже много времени с момента анонса технологии, этот сектор рынка развивается не очень динамично. Причем, виной тому и разрозненные несовместимые API. OpenCL и DirectCompute призваны решить данную проблему, но пока что стоит рассматривать GPGPU как приятное дополнение к впечатляющей графической производительности. Когда OpenCL был представлен в прошлом году, мы надеялись, что к моменту запуска Fermi появятся подходящие для конечного пользователя приложения, которые помогут сравнить эффективность решений AMD и NVIDIA. К сожалению, этого не произошло, и в нашем распоряжении имеются лишь синтетические тесты для формального сравнения GPU. Мы зафиксировали результаты карт в паре таких бенчмарков, но эти показатели стоит воспринимать реалистично — они недостаточно точно показывают скорость работы плат GeForce и Radeon, давая лишь условный ориентир. Начнем мы с OpenCL реализации N-Queens, разработанной PCChen с форумов Beyond3D. Этот бенчмарк использует инструменты OpenCL для нахождения решений известной шахматной задачи для доски заданного размера. Замеряется время проведения расчетов в секундах. В данном случае мы установили условный размер доски в 17x17 клеток и подождали, пока не будут найдены все доступные решения. 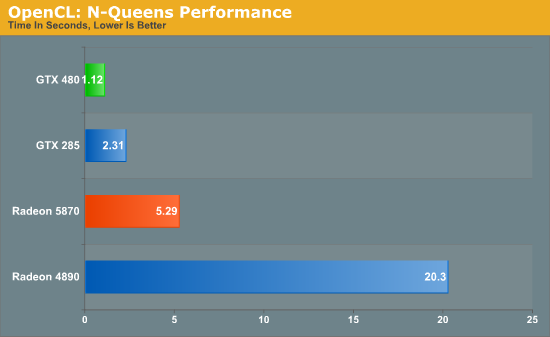 Вторым тестом был выбран пост-процессиноговый бенчмарк из утилиты GPU Caps Viewer. В ней силами OpenGL сначала рисуется тор, а затем на него накладываются различные эффекты с помощью OpenCL. На графике — фреймрейт данного процесса.
Источник: www.anandtech.com/ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||