Каталог
Знакомство с GTX 480 и GTX 470
Как вы уже знаете, на данный момент GF100 представлен двумя видеокартами: топовой GeForce GTX 480 и несколько более слабой GeForce GTX 470. Не стоит отождествлять название самой архитектуры Fermi и GF100. Данный чип является первым, и самым большим представителем нового поколения GPU, но отнюдь не единственным запланированным. Интересно, что ни одна из представленных карт не имеет на борту "полноценного" GF100. Ранее было известно, что GF100 содержит 512 SP, которые организованы в блоки по 4x16x32 модуля. И, хотя суффикс *80 характерен для топовых плат, даже в GTX 480 задействованы не все ядра. В наиболее быстрой на сегодня карте активно 480 SP, а в GTX 470 — 448. Так что, полной мощности GF100 сегодняшние карты не раскрывают. Возможно, в скором будущем мы увидим что-то вроде GTX 485 или GTX 490 со всеми работающими функциональными блоками. Или же не увидим. Это зависит от того, какова истинная причина некоторого урезания GPU для GTX 480 — недостаточно высокий процент выхода годных кристаллов, или же трудности в нахождении компромисса между производительностью, TDP и ценой.
Начнем мы знакомство с картами со старшей модели, GTX 480. В ней отключен 1 из 16 SM чипа GF100, а рекомендуемая для североамериканского рынка цена установлена на отметке $499, что автоматически определяет и конкурента в лице Radeon HD 5870. Заблокированный SM никак не повлиял на количество ROP, которые являются частью отдельного функционального блока, но пропорционально уменьшил возможности карты по текстурированию, обсчету шейдеров и тесселяции относительно гипотетического полнофункционального GF100. Таким образом, в распоряжении GTX 480 находятся 48 ROP и 768 Кб L2 кэша GF100 вместе с 60 текстурными модулями, 15 движками PolyMorph Engine и массивом в 480 потоковых процессоров. Хотя из-за значительных архитектурных изменений сравнивать количественные показатели платы с предшественниками некорректно (тогда как, например, проводить аналогии между Radeon HD 5000 и HD 4000 было легко), можно говорить, как минимум, об удвоении GTX 285 с точки зрения вычислительных возможностей и числа шейдерных процессоров. В свою очередь, GTX 470 является еще более урезанной платой, основанной при этом на все том же полноценном GF100 и предлагаемой производителями по цене в $349 (теоретически). Как уже было упомянуто ранее, в GTX 470 активно только 448 ядер, т.е. выключено уже 2 из 16 SM. Помимо блокировки ещё одного SM, NVIDIA деактивировала еще и 1 из 6 ROP кластеров, что повлекло за собой уменьшение количество модулей ROP на 6 единиц, урезание кэша на 128 Кб и потерю двух 32-битных каналов памяти. Таким образом, GTX 470 располагает 448 SP, работающими в паре с 40 ROP, 640 Кб кэша L2 и 320-битным интерфейсом GDDR5.
Как это обычно бывает с урезанными по функциональным блокам картами, GTX 470 получила и пониженные относительно GTX 480 частоты. В частности, ядро замедлили на 13%, до 607 МГц, пропорционально (до 1215 МГц) упала частота и шейдерного домена. С другой стороны, частота памяти была снижена лишь на 10%, до 837 МГц (3348 МГц эффективных). Все это вместе оставляет GTX 470 примерно 80% производительности в шейдерных, текстурных операциях и при тесселяции от GTX 480, и 72% по скорости ROP и пропускной способности шины памяти. Среди прочих характеристик карт особое удивление вызывают тактовые частоты памяти, которые были выбраны NVIDIA. Они оказались ниже наших ожиданий и максимальных стабильных частот плат семейства Radeon. Так, эффективные 5 ГГц уже не являются чем-то экстраординарным для GDDR5, однако NVIDIA не превысила и 3.7 ГГц. Возникает вопрос, почему было принято такое решение, но факт остается фактом — из-за данных сравнительно невысоких частот и меньшей, чем у GT200, ширине шины памяти, GTX 480 обладает лишь на 11% большей ПСП, чем GTX 285, тогда как GTX 470 даже отстает от этого ускорителя на 15%. С учетом относительно широкой 384-битной шины памяти, мы изначально предполагали, что NVIDIA столкнулась даже с большими проблемами, чем AMD с 5000 серией Radeon HD при организации стабильного обмена данными между GPU и чипами памяти. Однако оказалось, что причина низких частот кроется в другом. В действительности, проблема в собственном I/O контроллере NVIDIA, который еще далек от совершенства. В отличие от AMD, инженеры которой уже более двух лет имеют дело с GDDR5, проектировщики NVIDIA не слишком привычны к наиболее передовому стандарту памяти. Ведь первым продуктом NV с поддержкой GDDR5 только недавно (в прошлом году) стал бюджетный GT 240. Так что удивляться здесь особо нечему. Остается лишь ожидать, пока контроллер в будущих моделях плат отшлифуют настолько, чтобы сделать высокие тактовые частоты реальностью для 384-битной шины. Это вновь подводит нас к вопросу о вынужденном ускорении выпуска чипа. Понятно, что NVIDIA требовалось внедрять новую архитектуру и создавать заделы для роста, но, похоже, что выбранное для этого компанией время оказалось неудачным, и с задачей было справиться непросто. Потребовалось действительно много инженерных ресурсов для переработки структуры чипа, в конечном счете это вылилось в большие временные затраты и высочайшую сложность кристалла. Мало того, что 3 млрд. транзисторов на кристалл — величина, близкая к разумному пределу 40 нм техпроцесса, так еще и уровень выхода годных чипов невелик. Необходимость отключения одного из SM даже в топовом варианте карты для того, чтобы обеспечить доступность карт в приемлемые сроки, неотработанный контроллер памяти — все это несколько смазывает общее впечатление от продукта. Следящие за индустрией читатели возразят, что исторически для NV является нормой выпуск нового чипа на не слишком подходящем для этого техпроцессе с последующей оптимизацией. Так было и с G70 - G71 (7800GTX - 7900 GT), и в какой-то степени с G80 - G92 (8800 GTX - 8800 GTS 512), и с GT200 - GT200b (GTX 280 - GTX 285). Проблема лишь в том, что в прошлых поколениях NVIDIA была "на коне" и могла себе позволить релиз "доведенного до ума" чипа с некоторым опозданием. В случае же с внедрением Fermi, компания выступает в роли догоняющей, и хорошо видно, что GF100 выпущен в некоторой спешке, хотя решение об анонсе карт на его базе в кратчайшие сроки и было единственно верным. Не стоит воспринимать данные слова как критику в адрес NVIDIA. Следует понимать сложность разработки столь массивных чипов и осознавать, что каждое новое поколение GPU за дополнительные проценты производительности требует все больших затрат. Пускай определенные видеокарты получаются путем простого увеличения количества функциональных блоков образца прошлого поколения, необходимость периодического внедрения принципиально новых решений очевидна. И редко когда она происходит гладко. Стоит вспомнить один лишь R600 ATI, который был выпущен не просто с опозданием, но еще и показал недостаточную производительность (чего не скажешь о Fermi). Сегодня, с легкостью "умножив на два" RV770 и внедрив некоторые архитектурные новшества, AMD получила Cypress. Практически наверняка можно сказать, что такой фокус с Radeon HD 6000 уже не пройдет, и компании потребуется разработка новых базовых принципов GPU. А сейчас ещё непонятно, сможет ли ATI грамотно распорядиться имеющимся преимуществом во времени, не запоздав в следующем поколении, как уже было однажды. Хотя положение дел в индустрии и необходимо рассматривать в перспективе, не забывая при этом историю, для составления полной картины происходящего, в данный момент нас интересуют платы на основе GF100, которые имеются на руках и в скором времени будут доступны для приобретения. Из важных характеристик видеокарт мы пока еще не рассмотрели тепловыделение и энергопотребление. Ни для кого не должно стать сюрпризом, что с более чем 500 кв. мм чипом, изготовленным по 40 нм техпроцессу, GTX 480 и GTX 470 являются очень горячими. Заявленный TDP для старшего продукта составляет 250 Вт, для младшего — 215 Вт. В покое же карты потребляют 47 Вт и 33 Вт соответственно. NVIDIA всегда стремилась создавать максимально производительные GPU на одном кристалле, и это приводило к появлению плат с высоким энергетическим аппетитом. Но GTX 480 превзошел все ранее виденные нами карты по этому показателю; даже 65 нм GTX 280 не был столь горячим. Подробнее этот вопрос мы рассмотрим в разделе замеров энергопотребления. Естественно, в GTX 480/470 нас интересуют не только сами GPU, но и непосредственно платы. По какой-то причине NVIDIA вновь решила размещать микросхемы памяти лишь на лицевой стороне, а само число чипов и общий объем VRAM линейки GTX 400 опять оказались нестандартными. Так, на GTX 480 12 128Мб чипами GDDR5 набран общий объем видеопамяти в 1536 Мб, тогда как у GTX 470 10 чипов и 1280 Мб. Необходимо отметить, что это первое значимое увеличение объема памяти со времен представления 8800GTX с 768 Мб в 2006 году. С того момента большинство выпускаемой компанией карт оснащались 256/512-битной шиной памятью, связывающей чип с фреймбуффером объемом до 1 Гб. Более того, вполне вероятно, что грядущие карты будут иметь 3 Гб GDDR5 на борту, так как до конца этого года на рынке ожидается появление в массовых объемах 256 Мб чипов соответствующего стандарта. Что касается систем охлаждения, то NVIDIA пошла по необычному для себя пути. В отличие от серии GTX 200, GTX 480 и GTX 470 оснащаются двумя совершенно разными СО, так что карты довольно сильно различаются. На самом деле, GTX 470 является в этом смысле вариацией дизайна GTX 200, включая полностью закрывающий карту пластиковый кожух. На GTX 480 установлен кулер совершенно иной конструкции с пятью тепловыми трубками (четыре из них видны снаружи, одна остается внутри), который при этом не прикрыт никакими пластиковыми декоративными панелями. То, что вы видите на фото лицевой стороны GTX 480 — решетка верхней части радиатора. Довольно сложно сказать, насколько сильно улучшается качество охлаждения платы благодаря такому решению, но то, что пластина нагревается достаточно серьезно, чтобы легко обжечься, — факт.
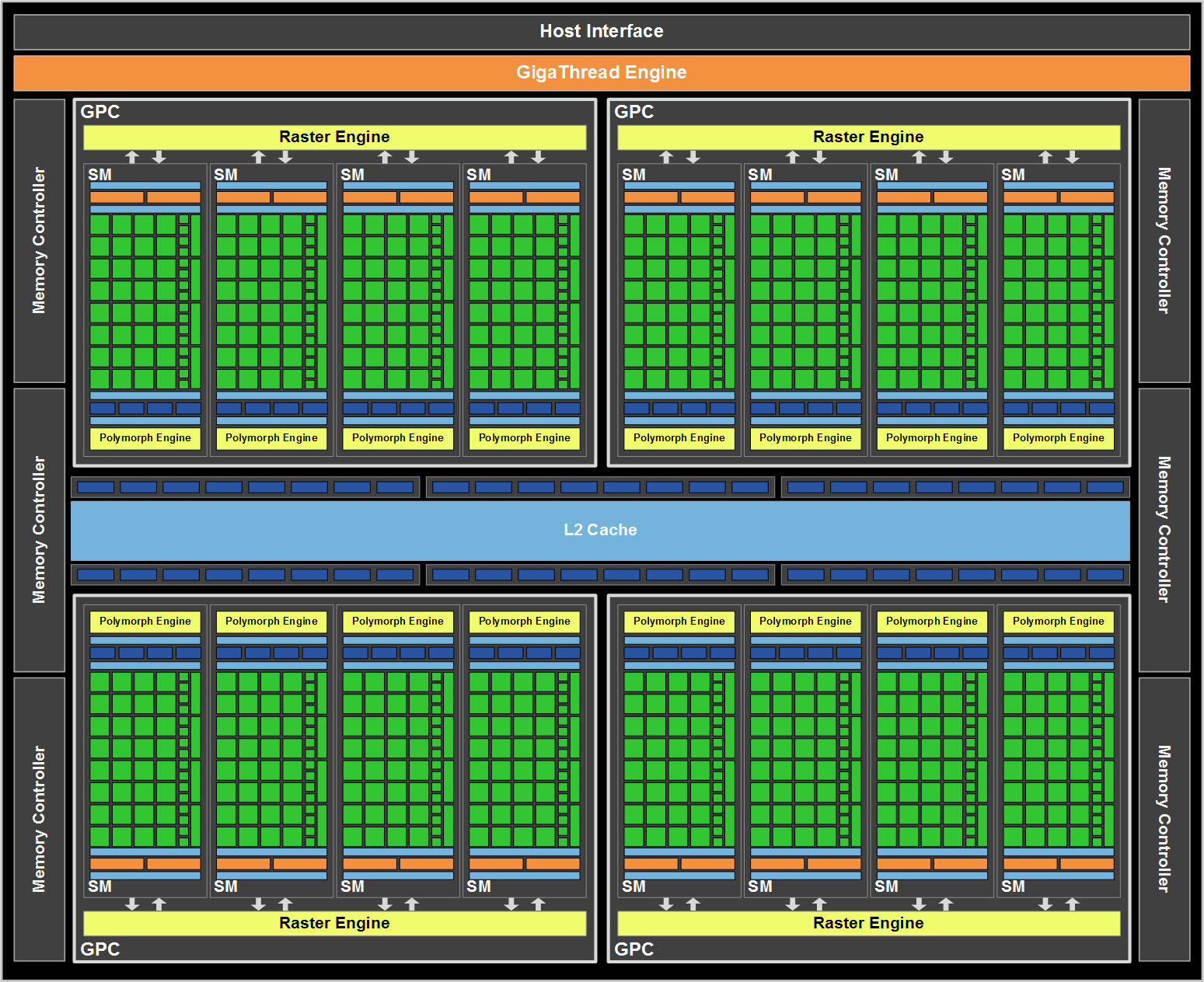
Еще одной интересной особенностью охлаждения новинок является прорезь в печатной плате, которая позволяет лопастям вентилятора засасывать воздух с обеих сторон карты. Такое решение не ново, на GTX 295 мы уже видели нечто подобное. Но на одночиповых платах на нашей памяти такой элемент дизайна появляется впервые. Хорошей новостью для владельцев компактных корпусов (если, конечно, среди энтузиастов high-end "железа" такие еще остались), являются компактные геометрические размеры карт. Так, GTX 470 занимает лишь 24.2 см в длину, что равняется Radeon HD 5850 (и на 2.54 см короче, чем GTX 200). Старший GTX 480 несколько длиннее, уже 26.7 см, но все равно немного меньше, чем GTX 200. Радует и то, что коннекторы питания PCIe размещены не на задней стороне печатной платы, как, например, у Radeon HD 5850, а на верхней; это облегчает подключение. Так что в реальности GTX 400 должны поместиться в большее количество корпусов, нежели основанные на Cypress карты AMD. Но, несмотря на довольно скромные требования по занимаемому пространству, из-за высокого TDP карты нуждаются в активных омывающих их потоках воздуха. В действительности, данная рекомендация справедлива для любых high-end карт, но для GTX 400 хочется обратить на нее внимание особенно. Более того, при эксплуатации плат в режиме SLI NV отдельно советует по возможности размещать видеокарты как можно дальше друг от друга. Казалось бы, это не является новостью, но только после реальной эксплуатации GTX 400 понимаешь, насколько важен этот пункт. Если одиночная GTX 480 еще не является большой проблемой в просторном продуваемом корпусе, то пара таких плат в SLI, расположенных рядом друг с другом (а ведь далеко не все материнские платы с тремя слотами PCIe 2.0 x16 обладают полноценной пропускной способностью интерфейса в любом слоте), требуют дополнительного прямого обдува вентилятором. Так что, не придавайте особого значения габаритам плат — из-за высокой степени нагрева им все равно необходим качественный корпус с несколькими вентиляторами. Перейдем к расположению портов вывода на GTX 400. При проектировании Evergreen AMD удалось сократить площадь эффективного "выхлопа" системы охлаждения благодаря приемлемому тепловому пакету и расположить дополнительный порт в верхней части брекета. NVIDIA же оказалась ограничена высотой однослотовой планки, способной вместить лишь два полноценных порта DVI. Но компания распорядилась имеющимся местом здраво, отправив на покой устаревший S-Video. На карте референсного дизайна присутствует два Dual-Link DVI порта и mini-HDMI (карта с таким интерфейсом попала в нашу тестовую лабораторию впервые). Следует помнить, что GF100 имеет лишь два полноценных RAMDAC, так что, хотя на платах и будет присутствовать три цифровых порта, одновременный вывод изображения возможен только по двум из них.  Кстати, раз уж мы упомянули о видеовыходах различных типов, остановимся подробнее на возможностях плат по выводу мультимедийного контента. Описать их можно кратко, так как в GF100 не появилось каких-либо нововведений на этот счет по сравнению с 40 нм GT 200, выпущенными в конце прошлого года. Это означает, что используется модуль VP4, способный на аппаратном уровне декодировать H.264/MPEG-2/VC-1/MPEG-4 ASP, а возможности передачи звука довольно ограничены. К сожалению, это равносильно тому, что все существующие сейчас карты GTX 400 и прочие ответвления Fermi первого поколения будут проигрывать по мультимедийным возможностям AMD Radeon 5000. Действительно, карты NVIDIA способны обрабатывать и передавать DD/DTS, как и несжатый восьмиканальный LPCM звук, но речи о HD форматах вроде DTS-HD и Dolby TrueHD не идет. Так что сегмент HTPC пока надежно остается в руках AMD. Что касается доступности, мы уже говорили о том, что проведенный 26 марта анонс был формальным. Лишь 12 апреля реальные карты должны были начать поступать в магазины США. Так что вряд ли стоит говорить о скорой доступности продуктов даже на "родном" рынке. NVIDIA утверждает, что располагает десятками тысяч видеокарт к моменту старта продаж, не уточняя при этом, о каких цифрах идет речь. Скажем, у AMD имелось 30 000 видеокарт 5800 к запуску, и они были раскуплены практически мгновенно. А в России лишь спустя пару месяцев стало возможным свободно приобрести 5870/5850 за рекомендуемую производителями для Европы сумму. К тому же, если говорить о ценовом позиционировании, NVIDIA находится заведомо в менее выигрышном положении. На рынке уже длительное время существует, и успешно продается быстрый конкурент, а 500 кв. мм кристаллы с 1.5 Гб видеопамяти сами по себе дешевыми быть не могут. Более того, после вывода Fermi на рынок, AMD, и без того обладающая большим пространством для маневра, заявила, что не будет реагировать на GF100 молниеносно и снижать цены. Лишь в скором времени ожидается 5870 с небольшим фейслифтингом — несколько поднятыми частотами. Так что надеяться на какие-то ценовые войны со стремительным снижением конечной стоимости карт не стоит. Как мы увидим в дальнейшем, AMD проигрывает не так много, чтобы идти на такие меры, а из-за высоких производственных издержек NVIDIA при возможности продавала бы GTX 480/470 и того дороже. [N4-Об архитектуре GF100] Итак, NVIDIA GeForce GTX 480 и 470 основаны на GPU под кодовым названием GF100, игровой версии архитектуры Fermi, которая была изначально представлена в сентябре прошлого года. GF100 служит базой для серии GeForce; чип, который NV так и называет, Fermi, предназначен для плат Tesla. Фактически они идентичны и различаются в деталях. На высоком уровне, GF100 выглядит как укрупненный GT200, но это впечатление ошибочно. Возьмем хотя бы начальную стадию работы чипа. До GF100 NVIDIA использовала большой унифицированный модуль, функции которого состояли в планировании задач для потоковых процессоров, установке граней треугольников, растеризации и отбрасывании невидимых поверхностей. Так это выглядит на общей диаграмме GT200:
Четверка серых блоков, расположенная сверху, обслуживает все вычислительные кластеры GPU. В GF100 же этот ранее основополагающий модуль утратил свою значимость: многие из его функций были отрезаны и перенесены на более низкие уровни конвейера рендеринга. За исключением планировщика задач чипа, все прочие функциональные блоки инженеры уменьшили в размерах, увеличив при этом их количество, и перенесли ближе к исполнительным модулям. Это было сделано для улучшения масштабируемости архитектуры. К тому же с увеличением размеров графических процессоров все сложнее становится заставить разделяемые многофункциональные части GPU работать эффективно. В прошлом NVIDIA поступала следующим образом при группировке своих GPU с унифицированной шейдерной архитектурой: объединялось несколько ядер, они наделялись кэшем, некоторым массивом общей памяти, а также парой блоков для специализированных задач (Special Function Unit, SFU). Все это вместе называлось потоковым мультипроцессором (Streaming Multiprocessor, SM). В GT200 тройка таких SM вместе с некоторым количеством текстурных модулей и текстурной кэш-памятью первого уровня (и определенным внутренним распределителем задач) образовывала текстурно-процессорный кластер (Texture/Processor Cluster, TPC). Флагман предыдущей генерации, GeForce GTX 280, имел в своем составе 10 таких TPC, которые и формировали вычислительную мощь чипа.
С переходом к GF100, NV отказалась от прошлого шаблона построения GPU и структуры TPC. Отныне чип состоит из кластеров обработки графики (Graphics Processing Cluster, GPC) и имеет намного больше SM. SM набраны 32 ядрами, и в одном GPC находится четыре SM. У каждого GPC имеется свой выделенный растровый движок, вместо использовавшегося ранее общего на весь чип блока. Из схемы понятно, что у GF100 всего четыре таких крупных GPC, но, как вы уже знаете, ни у одного из продаваемых сегодня GeForce на базе GF100 не активированы все имеющиеся SM.   Теперь все вычисления на уровне ядер соответствуют спецификациям IEEE. Речь идет о стандарте IEEE-754 2008 для вычислений с плавающей запятой (то же самое реализовано и в RV870/HD 5870) и полной поддержке 32-битной точности для целых чисел. Например, ранее умножение 32-битных целых приходилось эмулировать, аппаратно производилось лишь 24-битное умножение. Теперь все подобные проблемы, приводящие в определенных случаях к заметной потери производительности и, потенциально, даже к недостоверным результатам, остались в прошлом. Добавили |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Источник: www.anandtech.com/