Каталог
Общая функциональная схема GT200.Если вы еще не знакомы с унифицированной шейдерной архитектурой NVIDIA, крайне рекомендуем почитать соответствующие материалы, потому что при всех многочисленных изменениях GT200 является прямым наследником G80/G92 и перед прочтением данной части статьи лучше ясно представлять, чем отличаются, например, G71 и G80, чтобы понять, в чем преимущества GT200. Все базовые понятие, примененные NVIDIA впервые для G80, остались без изменений – архитектура все так же модульна. Самый низкий уровень, как и ранее, составляют потоковые процессоры (SP – Streaming Processor):
NVIDIA называет SP отдельным процессорным ядром, что, вообще говоря, соответствует действительности. Каждый SP является самым настоящим микропроцессором с очередным типом исполнения команд, обладающим полноценным конвейером, парой ALU и FPU. У SP нет кэш-памяти, так что сам по себе он не может быть эффективным в чем-то другом, кроме как в огромном количестве математических расчетов. Большинство времени SP и занимается обработкой пикселей и вершин, поэтому факт отсутствия кэша не является недостатком. Если пытаться найти пример для сравнения, Streaming Processor очень похож по структуре на упрощенную версию SPE в процессоре Cell, разработанном совместными усилиями Toshiba, IBM и Sony. Или же можно сказать, что SPE является упрощением SM, к которому мы сейчас перейдем. Кстати, если проводить сравнение дальше, SPE имеет семь исполнительных блоков, тогда как SP имеет лишь три. Но, как бы ни был хорош SP в качестве математического устройства, сам по себе он бесполезен. Хорошие результаты при графическом рендеринге, являющемся задачей отлично распараллеливаемой, может дать множество таких небольших потоковых процессоров, что NVIDIA прекрасно и осознает, увеличивая количество и объединяя их в группы с дополнительными координаторами. Как раз первым уровнем объединения и является упомянутый выше потоковый мультипроцессор, или SM – Streaming Multiprocessor:
Потоковый мультипроцессор представляет собой массив из восьми SP, которые находятся в группе с двумя модулями специальных функций SFU – Special Function Units. Каждый SFU содержит в своем составе четыре FPU, заточенные для трансцендентных операций (sin, cos и т.д.) и интерполяции, которые часто используются при расчетах, связанных, например, с анизотропной фильтрацией. Хотя NVIDIA и не афиширует этот факт, каждый SFU является в отдельности таким же полноценным микропроцессором, как и SP. В SM также входит диспетчер исполнения команд MT, который занимается распределением нагрузки по SP и SFU внутри группы. Вдобавок к SP, SFU и MT в мультипроцессоре содержится и небольшой объем памяти (16 Кб - сделано это специально, так как каждый SP работает со своим пикселем и общие объемы информации невелики), общий для всех процессоров. Это не кэш команд и данных в привычном нам понимании центральных процессоров, скорее просто 16 некий буфер для более эффективного распределения нагрузки на SP. Следующим уровнем объединения является кластер SM, называемый Texture/Processor Cluster (TPC):
Как уже было отмечено, унифицированная архитектура является модульной, и при желании можно легко изменять количество и соотношение различных блоков. Так NVIDIA и поступила, увеличив в одном кластере количество групп SM с двух в G80 до трех в GT200. Сама же структура блока TPC не претерпела изменений – помимо внутреннего контролирующего модуля TM в каждом SM добавлена еще более высокоуровневая управляющая логика и текстурный блок, в котором располагаются модули текстурной адресации и фильтрации, а так же текстурный кэш L1. Таким образом получается, что уже в одном кластере содержится множество процессоров – 24 SP и 6 SFU (напомним, что в G80 было 16 SP и 4 SFU). Если помните, именно отключением двух таких кластеров в полноценном GT200 (брак же надо как-то использовать, особенно учитывая огромную площадь кристаллов) и получена GeForce GTX 260. Легко продолжить тему модульности архитектуры NVIDIA – множество блоков TPC объединено в массив потоковых процессоров (SPA – Streaming Processor Array):
Мощь нового чипа и определяется этой структурой в целом. В G80 SPA состоял из 8 TPC, в GT200 их количество было расширено до 10. С учетом того, что в каждом TPC теперь три SM против двух ранее, общая вычислительная мощь GT200 на 87,5% превышает таковую в G80.
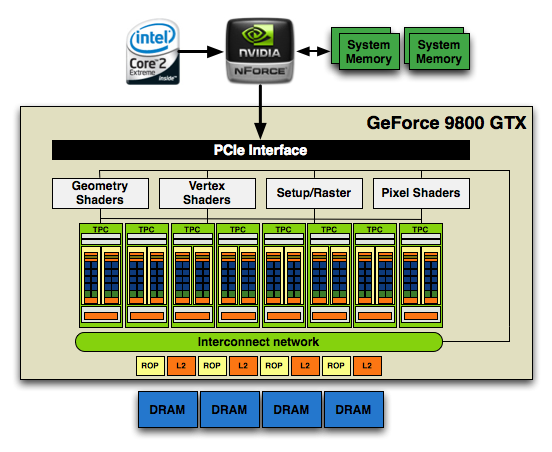
Еще уровнем выше располагается общая управляющая логика чипа, распределяющая и планирующая нагрузки на различные кластеры, контроллер PCI-Express 2.0 и шина Interconnect Network, соединяющая процессорную мощь SPA с уровнем L2 кэша текстур и блоками обработки растровой графики (Raster Operation Unit - ROP), которые в свою очередь уже имеют прямой доступ к фреймбуфферу. Вот так выглядит общая схема GT200 в сравнении с G92:
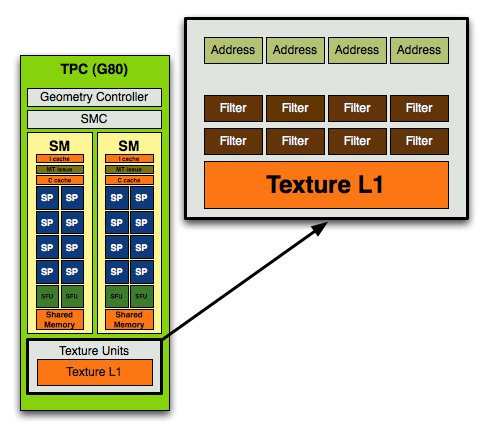
Как мы только что с вами убедились, GT200 получил огромную прибавку в чистой вычислительной мощности благодаря увеличению количества потоковых процессоров до 240 штук. Кстати, именно этот факт в наибольшей степени привел к такому огромному увеличению затрат транзисторов и огромным размерам самого кристалла. Нередко ATI в свое время ругали за то, что улучшая математические способности своих чипов, о текстурировании инженеры забывали, что приводило к дисбалансу в архитектуре. Компания объясняла это заделом на будущее, однако будущее это пришло видимо только сейчас, когда NVIDIA также при многократном усилении вычислительной мощи намного меньше внимания уделяет текстурным блокам. Вот так выглядел текстурный блок в TPC G80:
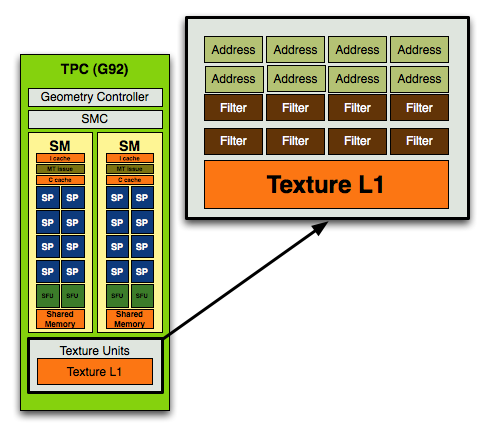
На 8 блоков фильтрации приходилось только 4 блока адресации. Уже в G92, а если быть точнее, в G84, соотношение блоков адресации и фильтрации стало равным:
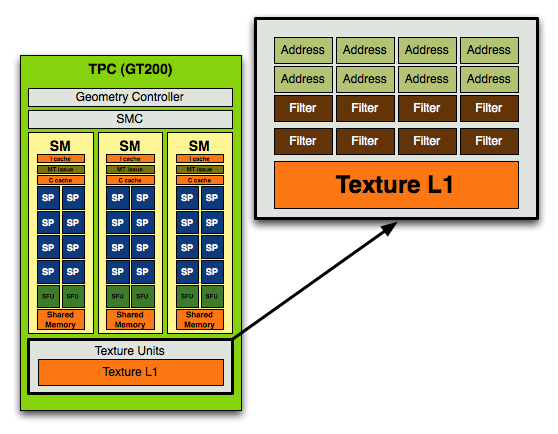
В GT200 такой состав сохранен, все те же 8 блоков адресации и 8 – фильтрации, однако получается, что увеличив вычислительную мощность, NVIDIA даже несколько ухудшила возможности текстурирования своего чипа. Не зря в представленных диаграммах блок текстурирования представлен не отдельно, а в составе TPC – работа SP и модулей адресации/фильтрации жестко связана, и если раньше на 16 SP в G80 приходилось 4/8 TAU/TFU, в G92 на 16 – 8/8, то теперь на 24 SP приходятся те же самые 8 блоков адресации и 8 фильтрации!
Тем самым мы имеем на 87,5% увеличившуюся вычислительную мощь, и лишь на 25% - текстурирования, что нарушает прежний баланс. Однако такие изменения сделаны далеко не просто так. NVIDIA намного лучше знать, каких операций используется в игровых приложениях на сегодняшний день больше – шейдерных, затрачивающих именно вычислительные силы чипа, или же текстурирования. Если бы при изменении баланса инженеры допустили ошибку, она не могла не сказаться при сравнении G80 и GT200 на одинаковых частотах – результат превосходства последнего был бы близок именно к минимальным 25%, а не к впечатляющим 87,5%. Достаточно лишь пролистать статью к этому сравнению, чтобы понять – никакой ошибки нет, сейчас уже окончательно пришло время преобладания вычислений над текстурированием. Интересно, что если копать глубже, можно найти сведения самой NVIDIA, что помимо количественных изменений в модулях текстурирования, их коснулись и изменения качественные – благодаря неким улучшениям в принципах работы эффективность текстурирования возросла на 22%. Нельзя забывать и об усовершенствованиях в блоках растеризации, которые внесла NVIDIA. Самое банальное – увеличилось их количество. В G80 за растеризацию отвечали 6 модулей ROP, каждый из которых за такт мог выдавать 4 пикселя, что в сумме составляло 24 пикселя. В GT200 добавили еще два ROP’а, и теперь с 8 модулями производительность достигает 32 пикселей за такт. Усовершенствованию подверглись и возможности блендинга – если G80 и G92 имели половинную скорость и за такт могли выполнять операцию блендинга лишь для половины из растеризованных пикселей, то GT200 лишился этого ограничения и блендинг теперь происходит ничуть не медленнее растеризации – выводить с блендингом можно все те же 32 пикселя за такт. Как результат – зачастую нелинейный прирост производительности везде, начиная от режимов с использованием антиалиасинга до обычных сцен с большим количеством шейдерных эффектов вроде теней или огня. [N5-Архитектура GT200 под микроскопом.]Помимо бросающихся в глаза изменений особо крупного масштаба, в GT200 NVIDIA ввела немало новшеств поменьше. Среди них особое место занимает модернизация распределяющей на потоковые процессоры нагрузку логики. От нее напрямую зависит насколько эффективно будут работать все 240 SP. Улучшения можно выразить простыми цифрами — если раньше один SM G80 мог исполнять 768 потоков команд, а сам чип управлялся с 12288, теперь каждый SM в состоянии разобраться с 1024 потоками, тогда как весь SPA, состоящий из 30 SM — с 30720. Инструменты для проверки данного утверждения, как и в случае с улучшенными возможностями текстурирования, у нас отсутствуют, однако не верить NVIDIA никаких поводов нет. С теми же самыми улучшениями в распределяющей и планирующей логике связана и повышенная относительно G80 эффективность выполнения в шейдере двух инструкций MAD+MUL за один такт. На самом деле, NVIDIA несколько лукавит, говоря об аппаратной поддержки данной возможности. Если бы исполнение проходило абсолютно на уровне математических процессоров, о таком понятии как процент удачных выполнений MAD+MUL не могло бы быть и речи. Дело в том, что одновременное исполнение двух инструкций (Dual Issue) возможно только тогда, когда планировщик TM группы SM, предвидя в коде возможность одновременного исполнения, зарезервировал за SFU время для выполнения, в общем-то, побочной для них функции MUL. С учетом того, что MAD будет выполнено SP, в таком случае можно говорить о возможности одновременного исполнения умножения и сложения, но в общем виде это не совсем верно. Причем случилось так, что неэффективная работа планировщика MT в G80 свела хорошую задумку NVIDIA по использованию свободных ресурсов для одновременного MAD+MUL к случайным удачам. В GT200, по словам компании, этот недостаток был устранен и в специальных оптимизированных тестах процент успешного выполнения составляет теперь 93-94%. Нельзя не сказать и об удвоении размера регистровых файлов. Как мы уже говорили, каждый SP является полноценным микропроцессором, и следовательно имеет регистровый файл. Регистры являются наиболее близкими к исполнительным модулям микропроцессора хранилищами информации, а регистровый файл — это все ячейки регистров суммарно. Хотя мы не знаем точно, каким размером регистрового файла обладал G80, точно известно, что в GT200 размер этого файла был удвоен. NVIDIA считает, что будущее игровых приложений за интенсивным использованием вычислительных ресурсов, следовательно частота использования регистровых файлов SP также должна возрасти, а ограничение может быть только одно — количественная нехватка этих самых регистров. Отсюда и логичное решение увеличить регистровый файл вдвое.
По данным NVIDIA такое увеличение очень неплохо сказывается в приложениях, использующих длинные шейдеры, например, 3D Mark Vantage. Еще одним важным нововведением GT200 и карт, основанных на этом чипе, стала аппаратная поддержка вычислений с плавающей запятой двойной точности. Удвоенная точность — условное название для 64-битных операций. Если говорить о 240 SP, они обладают стандартной 32-битной точностью и вообще не могут исполнять 64-битные команды. Для того, чтобы научить GT200 на аппаратном уровне поддерживать удвоенную точность вычислений, NVIDIA включила один 64-битный вычислительный блок в каждый SM, что составило общие 30 модулей на весь чип. Соотношение между процессорами в GT200, которые являются 32 и 64-битными крайне мало. Обусловлено это тем, что для основного применения видеокарт — графики, их использование очень ограниченно. Скорее 64-битная точность нужна в сложных научных расчетах, которые позволяет выполнять платформа CUDA. Даже если смотреть в будущее, очень маловероятно, что игры в скором времени будут получать пользу от обсуждаемого нововведения — сегодня основные вычисления приходятся на 8-ми битные целочисленные значения, да на 16-битные числа с плавающей точкой. Если заметные эффект от использования где-либо появится, то в первую очередь это скорее всего будет при обсчетах геометрии и вершин. Кстати о геометрии. Если у R600 и его более удачной версии RV670 с этим все было нормально, то у G80 наблюдались некоторые проблемы. К сожалению, это преимущество не было реализовано ATI и скорее играло на руку NVIDIA, так как разработчики игр редко использовали геометрические шейдеры в своих продуктах. Мы не можем ругать NVIDIA за слабую производительность G80 в геометрических вычислениях, так как в реальности оказалось, что новая возможность для разработчиков на тот момент не представляла интереса. Однако постоянно так продолжаться не могло, и в GT200 инженеры внесли нужные усовершенствования.
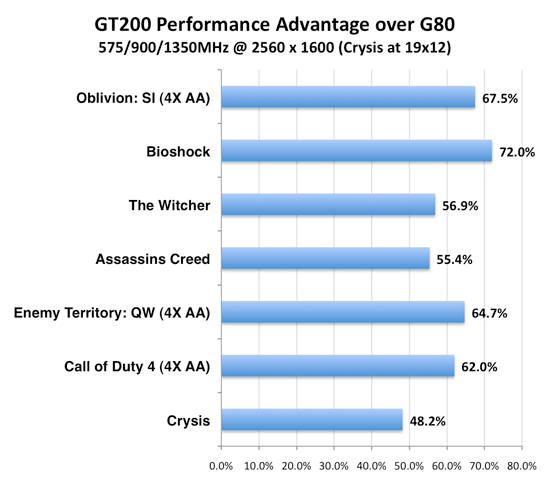
Как вы видите, преимущество GT200 над G80 достигает шести раз, и такую работу над ошибками нельзя не признать удачной. NVIDIA говорит и о более мелких усовершенствованиях в архитектуре своего нового чипа. Так, был переработан интерфейс взаимодействия между фреймбуффером и модулем data assembler, что привело к увеличенной скорости выборки проиндексированных примитивов. Благодаря увеличенным размерам кэшей пост-трансформации уменьшилось число простоев конвейера, более быстрыми стали переходы от вершинной и и геометрической стадий к viewport clip/cull. Была улучшена и производительность Z-Cull, тогда как с введением дополнительных ROP'ов количество возвратов Early-Z возросло. За такт теперь обрабатывается 32 пикселя, что соответствует 256 семплам в режиме 8x AA. [N7-Позиция NVIDIA в отношении DirectX 10.1 и отсутствие его поддержки в GT200.]Многие пользователи надеялись увидеть полноценную поддержку DX10.1 в GT200, однако этого не случилось — по решению NVIDIA в текущей архитектуре API не поддерживается полноценно. Положение, сложившееся сейчас, очень напоминает время, когда в R420 ATI отказалась от SM 3.0 в DX9, а NVIDIA продвигала их полную поддержку в серии GeForce 6. Только сейчас мы видим уже обратную картину — карты AMD поддерживают DX10.1 начиная с RV670, NVIDIA же отказывается реализовывать соответствие со стандартом даже в новом GT200. Что бы ни говорила о DX10.1, но чего-то принципиально нового это обновление для игроков не приносит. Скорее, это более удобные инструменты и новые возможности для разработчиков, позволяющий писать более оптимальный код. В некоторых случаях возможно существенное улучшение производительности. Необходимо отметить, что несмотря на тот факт, что NVIDIA не заявляет о поддержке DX10.1, а DX10 не предлагает caps bits, разработчики вполне могут реализовать запрос к драйверу о поддержке некоторых функций определенной функции. Так с GT200 может быть осуществлен multisample readback, и, при желании NVIDIA, многие другие нововведение DX10.1. Конечно, одной из позиций обновленного API являлось то, что разработчикам впредь не следовало задумываться о возможностях оборудования, для чего и были нужны caps bits, но это не значит, что инженеры NVIDIA не могли реализовать это несколько по-другому. Конечно, это поддержка некой единой возможности из целого ряда нововведений не позволяет сказать о том, что GT200 поддерживает DX10.1. Скорее NVIDIA реализовала некоторые возможности DX10.1, оставаясь в существующих рамках. Хотя мы бы и были рады видеть поддержку одинаковых API на картах AMD и NVIDIA, понять отказ NVIDIA от DX10.1 можно. На этом бы разговор про DirectX 10.1 можно было и закончить, если бы не очень честный маркетинг, который превратил обычное инженерное решение в предмет для неприятного обсуждения. Мы знаем, что в архитектуре как G80, так и R600, изначально была заложена поддержках некоторых функций DX10.1. В идеале неплохо бы было точно знать каких именно, и что было добавлено в GT200 для облегчения жизни разработчикам. К сожалению, ответ на этот вопрос был дан не техническим инженером NVIDIA, а подразделением технического маркетинга: "Мы поддерживаем лишь multisample readback, и это единственная возможность DX10.1, которую (некоторые) разработчики предпочли бы использовать. Если мы открыто скажем, какие функции не могут поддерживаться нашим аппаратным обеспечением, ATI постарается заставить разработчиков использовать их, что только повредит индустрии ПК игр и разочарует геймеров." Фактически, спорным в данном утверждении (а это, заметьте, официальная позиция NVIDIA) является чуть ли не каждая позиция: массивы кубических карт достаточно удобны для упрощения и ускорения многих приложений. Необходимо? Нет, но очень даже полезно? Да. Новые режимы раздельного MRT-блендинга могут стать часто используемыми с распространением техники отложенного рендеринга? Да, вполне! К тому же поддержка этой функции даст разработчикам дополнительный простор для экспериментов. Да, возможно немногие станут использовать Int16 для бленда, но в любом случае многие из возможностей DX10.1 интересны, и могли бы стать востребованными при обоюдной поддержке AMD и NVIDIA. Дальше стоит разоблачить и идею о том, что ATI намеренно будет пытаться нанести вред ПК-геймингу. Любой разработчик ставит перед собой задачу как можно более эффективно и быстро достичь поставленных целей, при этом затрачивая как можно меньше ресурсов. Если некая возможность при стремлении к результату будет полезной — почему бы не использовать ее? Если она бесполезна — проще оставить. Разработчики всегда стараются сделать как можно более интересную игру, причем доступную для большинства геймеров в равной мере использующих видеокарты AMD и NVIDIA. А возможно это только в случае поддержки одних и тех же API обоими вендорами. Так же, как NVIDIA приняла инженерное решение отказаться от DX10.1, каждый разработчик при производстве игры принимает решение об использовании определенной техники рендеринга, а так как NVIDIA не поддерживает DX10.1, то и функции этого API автоматически становятся менее привлекательными для применения, потому что в любом случае придется писать аналог на более старом DX10. Если это условие невыполнимо, или вариант кода DX10 будет работать на порядок медленнее, смысл применения DX10.1 стремится к нулю, и никакое давление AMD тут не поможет. Очень наивны и высказывание о том, что NVIDIA собирается спрятать от AMD недокументированные возможности GT200. Обе компании всегда занимаются реверс-инжинирингом, и, используя сверхмощные электрические микроскопы в сочетании с рентгеновскими лучами узнают все, что нужно о кристаллах конкурентов. NVIDIA прекрасно знает, что AMD, конечно же, изучит таким образом GT200, как в свое время NVIDIA сама изучала, например, RV670. Поэтому AMD сама, безо всяких сведений от калифорнийской корпорации, будет знать все сильные и слабые стороны решения конкурента. Кто же действительно пострадает от скрытности NVIDIA? В первую очередь это энтузиасты, которые любят изучать низкоуровневую работу аппаратного обеспечения. Конечно, это и разработчики, которые в неразберихе вокруг поддержки DX10.1 не могут понять, какие функции API NVIDIA реально может предложить. AMD, в свою очередь, не сможет предоставить реальные преимущества своих карт разработчикам, которые, скорее всего, откажутся от использования DX10.1, потому что чипы NVIDIA не поддерживают его (даже если и реально могут поддерживать, точной информации об этом нет). Ну и, в конце концов, среднестатистические геймеры, которым и не надо знать, что разработчик мог бы потратить время, сэкономленное при использовании DX10.1, например, на дополнительный сюжетный эпизод игры. Почему же все-таки NVIDIA выбирает путь нечестного маркетинга и не соответствующих реальности заявлений? Гадать можно долго, и точного ответа мы не знаем. Возможно этим компания хочет заставить разработчиков вообще отказаться от применения в играх кода, который хорошо работает на картах AMD (вспомните патч DX10.1 для Assassin's Creed, поднявший производительность карт AMD на пару десятков процентов), возможно функции DX10.1 хотя и могут быть реализованы, но скорость их выполнения оставляет желать лучшего, а времени на исправление упущений у инженеров уже не было. Реален и такой вариант, что текущая реализация архитектуры вообще не способна выполнять какие-либо необходимые функции, чтобы соответствовать требованиям DirectX 10.1. Но как бы там ни было, NVIDIA настаивает на том, что если откроет весь список поддерживаемых возможностей, AMD с ее, видимо, огромными денежными запасами купит определенных разработчиков, заставив поддерживать DX10.1, который решения NVIDIA запускать попросту не могут. Подождите-ка. Это говорит NVIDIA, придумавшая программу NSIST On NVIDIA и The Way It's Meant To Be Played? О компании, стоимость которой с ее графическим и процессорным подразделениями вместе взятыми в пару раз меньше самой NVIDIA, да и долг составляет миллиард долларов? Да уж, кто же действительно в состоянии купить разработчиков и негативно влиять на индустрию? [N8-Сравнение производительности G80 и GT200 на одинаковых частотах.]Из предыдущих частей статьи мы уже поняли, насколько сильно различается архитектура GT200 и G80/G92. Некоторые выводы о превосходстве нового чипа над старым поколением, сделанные нами при анализе, было интересно подтвердить проверкой обеих карт на одинаковых частотах. Для этого помимо самой GTX 280 мы взяли 8800 GTX, установив частоты работы обоих GPU на отметке в 575 МГц. Шейдерные процессоры работали на 1350 МГц, а память — на 900 МГц (1800 МГц эффективных). Графики ниже показывают, насколько увеличилась производительность от добавления вычислительной мощности, расширения шины памяти и всех тех усовершенствований, о которых мы говорили:
Согласно нашим предположениям, минимальный прирост мы могли увидеть на уровне 25% в тех случаях, когда для G80 узким местом являлось текстурирование, а вычислительная мощь не требовалась. В реальных приложениях, конечно, такой рост производительности выглядит маловероятным, и эффект от большего числа шейдерных процессоров должен приблизить превосходство GT200 над G80 к отметке в 87,5%. Как видно, наши предположения оправдались, и рост скорости как раз находится между двумя крайними величинами. Основываясь на полученных результатах можно сказать, что, например, Bioshock задействует максимальное количество вычислительной мощности, тогда как остальные параметры не являлись узким горлышком даже в G80. Crysis же, с другой стороны, показывает, что игре необходимо больше возможностей по всем позициям, а значительное улучшение лишь математического аппарата не приводит к скачкообразному повышению производительности. Приведенные выше данные лишь подтверждают, что производительность при измененном балансе архитектуры будет напрямую зависеть от используемых приложения. Там, где основные потребности состоят в математической мощности, GT200 будет получать самую заметную прибавку относительно решений предыдущих поколений. Там же, где текстурирование играет роль поважнее — потоковые процессоры чипа будет просто простаивать без дела. [N9-Управление питанием и энергосбережение.]Сегодня многие производители серьезно озабочены проблемами энергопотребления. Если раньше зачастую о возможности снижения частот в простое и хорошем соотношении производительности на Вт говорили просто как о приятных дополнениях, сегодня без этого не обойтись. NVIDIA, похоже, забыла об этом, так как несколько серий подряд в ее картах не было даже разделения частот на 2D/3D, однако с GT200 все встало на должные места — компания заявляет, что в состоянии простоя карта потребляет всего лишь 25 Вт. Примененные для этого технологии отнюдь не являются революционными. Применено самое обычное динамическое управление частотами и напряжениями. В GPU находится специальный датчик, отслеживающий степень загруженности видеопроцессора. В различных условиях работы (Hybrid Power — полное отключение видеокарты и переход на встроенную графику, 2D режим/простой, проигрывание HD видео, 3D графика с полной загрузкой, наконец) он выбирает соответствующие параметры. Переключения между режимами занимает считанные миллисекунды. В целом технология очень похожа на AMD PowerPlay. Конечно, с кристаллом огромных размеров и большим количеством набортной видеопамяти просто невозможно всегда удерживать энергопотребление в приемлемых рамках — когда карта использует все возможности, напряжения и частоты поднимаются, как поднимается и затрачиваемая энергетическая мощность, конвертируемая в десятки FPS и сотни Вт выделяемого тепла. Даже сложно сказать, что выглядит более впечатляющим — огромный горячий монстр в работе, или он же в спящем состоянии. Стоит отметить, что для режима проигрывания HD видео NVIDIA выделила отдельный режим работы с энергопотреблением с в 32 Вт. Приятно, что даже таким мелочам уделяется внимание. Конечно, если говорить о потребляемой мощности в целом, карту уровня GTX 280 можно сравнить с дорогой спортивной машиной, покупатели которой не задумываются о потреблении топлива, но ведь согласитесь, что всегда приятнее пусть даже в 2D режиме не тратить впустую десятки Вт энергии.
Источник: www.anandtech.com/ | |||||||||||||||||