Каталог
Технические спецификации референсных карт.На сегодняшний день NVIDIA предлагает две уже упомянутых выше модификации GT200 – это GeForce GTX 280 и 260. В таком законченном виде предстают перед нами обе карты:
Никаких значимых различий ни в сложной 14-ти слойной печатной плате, ни в схеме питания, ни в конструкции систем охлаждения между ними нет. Карты идентичны за исключением разъемов питания PCI-E (пара шестиштырьковых на GTX 260 и восьмиштырьковый в дополнение к одному шестиштырьковому на GTX 280), ну и, конечно же, установленного GPU и объема памяти.
В GTX 280 GT200 раскрывается во всей красе – активны все 240 потоковых процессоров, они работают на более чем удвоенной частоте в 1,296 ГГц относительно остальных блоков GPU, которые тактованы на 602 МГц. 1 Гб быстрой GDDR3, эффективная частота которой составляет 2,2 ГГц (1107 МГц реальная), связана с чипом по широкой 512-битной шине. В пике нагрузки карта потребляет до 236 Вт.
GeForce GTX 260 обладает несколько более скромными характеристиками, однако и цена его ниже. Покупателям предлагается 192 потоковых процессора, полученных путем отключения двух кластеров обработки текстур (Texture Processing Cluster - TPC) (модульность архитектуры сохранена), работающих на несколько сниженной относительно GTX 280 частоте в 1242 МГц (остальные блоки – 576 МГц). Такие несколько странные результирующие частоты обусловлены применением тактового генератора, знакомого нам по картам серии 9600 с G94 на борту – шаг изменения частот равен 27 МГц. Частота памяти при этом снижена до 2 ГГц (реальные 999 МГц), а объем и шина соответствуют количеству 64-битных контроллеров – если на полноценной GTX 280 их 8, то на GTX 260 на один меньше, отсюда и 896 Мб и 448-бит. Плата потребляет несколько меньше энергии, ограничиваясь 183 Вт.
Системы охлаждения карт обладают уже ставшей для NVIDIA классической двухслотовой конструкцией – расположенная под небольшим углом турбина продувает горячий воздух через радиатор с тепловыми трубками и выносит его из корпуса через отверстия на задней панели. Как и на более старых топах лицевую сторону карты закрывает пластина, контактирующая с наиболее горячими элементами, такими как чипы памяти и цепи питания. К ней в пару для более эффективного отвода тепла теперь добавлена еще одна пластина уже на обратной стороне платы. Цельный вид устройству придает пластиковый корпус, состоящий из двух половинок, имеющий схожую с 9800GX2 конструкцию. Что касается непосредственно эффективности, как и в случае с 8800 GTX и 9800 GTX она на высоте – даже столь горячая карта охлаждается достаточно хорошо. Уровень шума же не сильно порадует вас, если прошлыми картами были 8800 GTX/GTS, или же 9800 GTX. Турбина гонит больше воздуха, перемещая более горячие тепловые массы, отсюда и результат. NVIDIA срочно стоит переводить карты на 55 нм техпроцесс, и не только для того, что бы умерить их пыл, как вы увидите дальше.
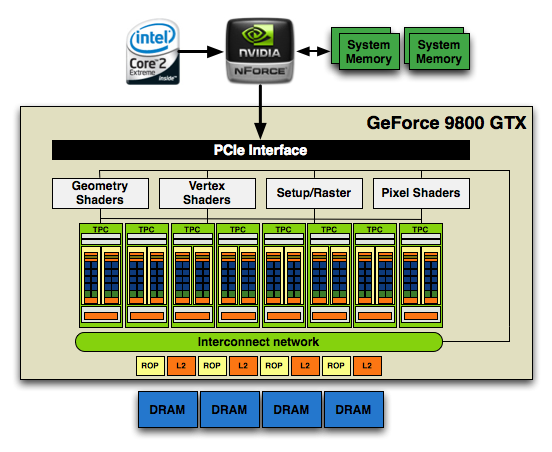
Завершая разговор о платах, стоит сказать и о поддерживаемых интерфейсах. Как и в случае с G80, выходные цепи GT200 вынесены в отдельный чип NVIO, теперь уже второго поколения. Последний обеспечивает как пару стандартных Dual-Link DVI, так и возможность построения полноценного HTPC на базе GeForce GTX 2x0 – судите сами, используя S/PDIF разъем на карте и адаптер DVI-HDMI можно вывести множество звуковых стандартов – от обычного LPCM стерео до 6-ти канального DTS. К сожалению, более продвинутые варианты вроде Dolby TrueHD или DTS HD-MA не поддерживаются. Что интересно, на аппаратном уровне реализована поддержка новомодного DisplayPort, однако места ему на картах референсного дизайна не нашлось. [N3-Общая функциональная схема GT200.]Если вы еще не знакомы с унифицированной шейдерной архитектурой NVIDIA, крайне рекомендуем почитать соответствующие материалы, потому что при всех многочисленных изменениях GT200 является прямым наследником G80/G92 и перед прочтением данной части статьи лучше ясно представлять, чем отличаются, например, G71 и G80, чтобы понять, в чем преимущества GT200. Все базовые понятие, примененные NVIDIA впервые для G80, остались без изменений – архитектура все так же модульна. Самый низкий уровень, как и ранее, составляют потоковые процессоры (SP – Streaming Processor):
NVIDIA называет SP отдельным процессорным ядром, что, вообще говоря, соответствует действительности. Каждый SP является самым настоящим микропроцессором с очередным типом исполнения команд, обладающим полноценным конвейером, парой ALU и FPU. У SP нет кэш-памяти, так что сам по себе он не может быть эффективным в чем-то другом, кроме как в огромном количестве математических расчетов. Большинство времени SP и занимается обработкой пикселей и вершин, поэтому факт отсутствия кэша не является недостатком. Если пытаться найти пример для сравнения, Streaming Processor очень похож по структуре на упрощенную версию SPE в процессоре Cell, разработанном совместными усилиями Toshiba, IBM и Sony. Или же можно сказать, что SPE является упрощением SM, к которому мы сейчас перейдем. Кстати, если проводить сравнение дальше, SPE имеет семь исполнительных блоков, тогда как SP имеет лишь три. Но, как бы ни был хорош SP в качестве математического устройства, сам по себе он бесполезен. Хорошие результаты при графическом рендеринге, являющемся задачей отлично распараллеливаемой, может дать множество таких небольших потоковых процессоров, что NVIDIA прекрасно и осознает, увеличивая количество и объединяя их в группы с дополнительными координаторами. Как раз первым уровнем объединения и является упомянутый выше потоковый мультипроцессор, или SM – Streaming Multiprocessor:
Потоковый мультипроцессор представляет собой массив из восьми SP, которые находятся в группе с двумя модулями специальных функций SFU – Special Function Units. Каждый SFU содержит в своем составе четыре FPU, заточенные для трансцендентных операций (sin, cos и т.д.) и интерполяции, которые часто используются при расчетах, связанных, например, с анизотропной фильтрацией. Хотя NVIDIA и не афиширует этот факт, каждый SFU является в отдельности таким же полноценным микропроцессором, как и SP. В SM также входит диспетчер исполнения команд MT, который занимается распределением нагрузки по SP и SFU внутри группы. Вдобавок к SP, SFU и MT в мультипроцессоре содержится и небольшой объем памяти (16 Кб - сделано это специально, так как каждый SP работает со своим пикселем и общие объемы информации невелики), общий для всех процессоров. Это не кэш команд и данных в привычном нам понимании центральных процессоров, скорее просто 16 некий буфер для более эффективного распределения нагрузки на SP. Следующим уровнем объединения является кластер SM, называемый Texture/Processor Cluster (TPC):
Как уже было отмечено, унифицированная архитектура является модульной, и при желании можно легко изменять количество и соотношение различных блоков. Так NVIDIA и поступила, увеличив в одном кластере количество групп SM с двух в G80 до трех в GT200. Сама же структура блока TPC не претерпела изменений – помимо внутреннего контролирующего модуля TM в каждом SM добавлена еще более высокоуровневая управляющая логика и текстурный блок, в котором располагаются модули текстурной адресации и фильтрации, а так же текстурный кэш L1. Таким образом получается, что уже в одном кластере содержится множество процессоров – 24 SP и 6 SFU (напомним, что в G80 было 16 SP и 4 SFU). Если помните, именно отключением двух таких кластеров в полноценном GT200 (брак же надо как-то использовать, особенно учитывая огромную площадь кристаллов) и получена GeForce GTX 260. Легко продолжить тему модульности архитектуры NVIDIA – множество блоков TPC объединено в массив потоковых процессоров (SPA – Streaming Processor Array):
Мощь нового чипа и определяется этой структурой в целом. В G80 SPA состоял из 8 TPC, в GT200 их количество было расширено до 10. С учетом того, что в каждом TPC теперь три SM против двух ранее, общая вычислительная мощь GT200 на 87,5% превышает таковую в G80.
Еще уровнем выше располагается общая управляющая логика чипа, распределяющая и планирующая нагрузки на различные кластеры, контроллер PCI-Express 2.0 и шина Interconnect Network, соединяющая процессорную мощь SPA с уровнем L2 кэша текстур и блоками обработки растровой графики (Raster Operation Unit - ROP), которые в свою очередь уже имеют прямой доступ к фреймбуфферу. Вот так выглядит общая схема GT200 в сравнении с G92:
Как мы только что с вами убедились, GT200 получил огромную прибавку в чистой вычислительной мощности благодаря увеличению количества потоковых процессоров до 240 штук. Кстати, именно этот факт в наибольшей степени привел к такому огромному увеличению затрат транзисторов и огромным размерам самого кристалла. Нередко ATI в свое время ругали за то, что улучшая математические способности своих чипов, о текстурировании инженеры забывали, что приводило к дисбалансу в архитектуре. Компания объясняла |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Источник: www.anandtech.com/